NOTE: the 2LT project is moving to: 2LT at Google Code.
A two-level data transformation consists of a type-level transformation of a data format coupled with value-level transformations of data instances corresponding to that format. Examples of two-level data transformations include XML schema evolution coupled with document migration, and data mappings that couple a data format mapping with conversions between mapped formats.
In the 2LT project we apply theories of calculational data refinement and of point-free program transformation to two-level transformations.
DATA REFINEMENT
A refinement of an abstract type A into a concrete type B, is witnessed by conversion functions to:A->B (injective and total) and from:B->A (surjective and partial).
TYPE-CHANGING REWRITES
Such data refinements can be modeled by a type-changing rewrite system, where each rewite step takes the form A => (B,to,from). In other words, each step produces not only a new type, but also the conversion functions between the old and new type. By repeatedly applying such rewrite steps, complex conversion functions are calculated incrementally while a new type is being derived.
PROGRAM CALCULATION
The complex conversion functions derived after type-changing rewriting can be subjected to subsequent simplification using laws of point-free program calculation. The same holds for compositions of conversion functions with queries on the target or source data types. Such simplifications then amount for instance to:
generation of efficient low-level data migrations from high-level migrations
program migration of queries on the source data type to queries on a target data type
Apart from transformation of point-free functions, we have implemented rewrite systems for transformation of structure-shy functions (XPath expressions and strategic functions), and for transformation of binary relation expressions.
HASKELL IMPLEMENTATION
We have implemented both type-changing rewrite systems and type-preserving rewrite systems in Haskell. The implementations involve generalized algebraic datatypes (GADTs), strategy combinators, type-safe representations of types and of functions, and other advanced Haskell techniques.
Alcino Cunha, Joost Visser. Strongly Typed Rewriting For Coupled Software Transformation. In Proceedings of RULE 2006, ENTCS, to appear. (PDF).
Pablo Berdaguer, Alcino Cunha, Hugo Pacheco, Joost Visser. Coupled Schema Transformation and Data Conversion For XML and SQL. In PADL 2007: Practical Aspects of Declarative Languages, to appear. (PDF).
Alcino Cunha and Joost Visser, Transformation of Structure-Shy Programs, Applied to XPath Queries and Strategic Functions, In Proceedings of the 2007 ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation, PEPM 2007, to appear. (PDF)
Claudia Mónica Necco, José Nuno Oliveira, and Joost Visser, Extended Static Checking By Strategic Rewriting of Pointfree Relational Expressions, Draft of februari 3, 2007. (PDF)
TECHNICAL REPORT
Alcino Cunha, José Nuno Oliveira, Joost Visser. Type-safe Two-level Data Transformations -- with derecursivation and dynamic typing, DI-Research.PURe-06.03.01, March 2006. (PDF).
The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined. On the one hand, it includes experiments of expressing VDM's data types (e.g. maps, sets, sequences), data type invariants, pre- and post-conditions, and such within the Haskell language. On the other hand, it includes the translation of VDM specifications into Haskell programs.
This is a continuation (or revival) of the original Camila system, see http://camila.di.uminho.pt.
The Camila revival project is being developed in distinct phases, which are briefly described below.
Phase I (Camila Revival)
Deliverables:
Prototype camila interpreter in Haskell
Camila Prelude modules in Haskell
Both deliverables are integrated into the UMinho Haskell Software distribution.
Documents
"PURe CAMILA: A system for software development using formal methods" - Alexandra Mendes and João Ferreira, LabMF 2005 - (Report) (Slides)
Examples
In directory Camila/Examples you will find some examples (if you intend to add examples, you sould put them in this directory too). Before loading them in the interpreter,
you will need to compile it. For example, to use the example Folder:
From libraries directory, run ghc --make Camila/Examples/Folder.hs -package plugins
From tools/Camila directory and after compiling the interpreter:
make run
:l Camila.Examples.Folder
create f := new Folder
eval f opread
(If you want to see more examples, please see Report -- Chapter 5 )
Phase II (VDM++ features)
VDM++, in comparison with VDM has the following extra features:
Allows the definition of classes and objects
Inheritance (specialization and generalization)
Operations and functions to describe functional behaviour of the objects
This report explains how to mimic VDM++ features (parallelism not included) in Haskell.
Phase III (Camila enriched with components)
(to appear)
Downloads
You can find the latest version of CAMILA in Research.PURe CVS (see PUReSoftware). You will need hs-plugins package.
To use the prototype interpreter, you have to compile it (just run make in directory tools/Camila) -- don't forget you need to install hs-plugins package before doing this.
To run it just do make run.
Note: At the moment, you will have to compile all the examples you want to run.
(All these steps will be simplified in the future, so stay tuned)
A stand-alone release is also available:
ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection:
JReach: derives package graphs from Java sources, and allows them to be sliced or chopped according to various criteria.
JReach
A package graph contains nodes that represent Java packages and types (interfaces or classses) and their interrelationships. A package graph contains edges to represent the following types of relationships:
nesting: a type is nested inside a package or inside another type.
import: a type imports other types.
inherit: a type inherits from another type (class from class, or interface from interface).
Using JReach, one can compute slices and chops of the above package graph. For instance, the forward slice from software_improvers.clonedetection.metric.CloneDetector:
Or the backward slice from java.util.List and java.util.ArrayList:
And finally, the chop between software_improvers.clonedetection.metric.CloneDetector on one hand, and java.util.List and java.util.ArrayList on the other hand:
Additionally, JReach also allows to compute the union between slices rather than the intersection.
Graph slicing and chopping
The ChopaChops tools use functionality from the UMinho Haskell Libraries for representing and manipulating graphs. In particular, they use the modules in the Relation package.
CoddFish makes extensive use of heterogenous collections and type-level programming.
HETEROGENEOUS COLLECTIONS
A relational database is modeled as a heterogeneous collection of tables. A table, in turn, is modeled as a heterogeneous collection of attributes (the header of the table) and a Map of key values to non-key values (the rows of the table). Both the key and non-key values are stored again in a heterogeneous collection. In addition, heterogeneous collections are used to model the arguments and results of database operations, and to model functional dependencies.
TYPE-LEVEL PROGRAMMING
Type-level programming is used to maintain the consistency between header and rows, and between functional dependencies and tables. Type-level predicates are provided to check whether tables and functional dependencies are in particular normal-forms, or not.
RESEARCH PAPER
The essentials of CoddFish are described in the following paper:
Alexandra Silva and Joost Visser, Strong Types for Relational Databases (Functional Pearl). In Proceedings of Haskell Workshop 2006, to appear. pdf
API
Generated documentation of the API of CoddFish will appear here.
Downloads.
CoddFish is a sub-library of the UMinho Haskell Libraries. A stand-alone release is also available:
HaGLR provides support for Generalized LR parsing in Haskell.
Documentation
João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing in Haskell. Paper presented at the 5th summer school on Advanded Functional Programming.
Haddock documentation: see PUReSoftware, in particular the modules under Language.ContextFree.
João Fernandes. Generalized LR Parsing in Haskell. Technical report DI-Research.PURe-04.11.01. pdf
Haskell Activities and Communities Report
Entries submitted by the LMF group at the Informatics Department of the University of Minho.
[Libraries]
1. Pointless Haskell
Pointless Haskell is a library for point-free programming with recursion patterns defined as hylomorphisms. It is part of the UMinho Haskell libraries that are being developed at the University of Minho. The core of the library is described in "Point-free Programming with Hylomorphisms" by Alcino Cunha.
Pointless Haskell also allows the visualization of the intermediate data structure of the hylomorphisms with GHood. This feature together with the DrHylo? tool allows us to easily visualize recursion trees of Haskell functions, as described in "Automatic Visualization of Recursion Trees: a Case Study on Generic Programming" (Alcino Cunha, In volume 86.3 of ENTCS: Selected papers of the 12th International Workshop on Functional and (Constraint) Logic Programming. 2003).
The Pointless Haskell library is available from http://wiki.di.uminho.pt/bin/view/Alcino/PointlessHaskell.
[Tools]
1. DrHylo?DrHylo? is a tool for deriving hylomorphisms from Haskell program code. Currently, DrHylo? accepts a somewhat restricted Haskell syntax. It is based on the algorithm first presented in the paper Deriving Structural Hylomorphisms From Recursive Definitions at ICFP'96 by Hu, Iwasaki, and Takeichi. To run the programs produced by DrHylo? , you need the Pointless library.
DrHylo? is available from http://wiki.di.uminho.pt/bin/view/Alcino/DrHylo.
2. VooDooMVooDooM reads VDM-SL specifications and applies transformation rules to the datatypes that are defined in them to obtain a relational representation for these datatypes. The relational representation can be exported as VDM-SL datatypes (inserted back into the original specification) and/or SQL table definitions (can be fed to a relational DBMS). The first VooDooM prototype was developed in a student project by Tiago Alves and Paulo Silva. Currently, the development of VooDooM is continued in the context of the IKF-P project (Information Knowledge Fusion, http://ikf.sidereus.pt/) and will include the generation of XML and Haskell
VooDooM is available from http://wiki.di.uminho.pt/bin/view/Research.PURe/VooDooM.
3. HaLex?HaLeX? is a Haskell library to model, manipulate and animate regular languages. This library introduces a number of Haskell datatypes and the respective functions that manipulate them, providing a clear, efficient and concise way to define, to understand and to manipulate regular languages in Haskell. For example, it allows the graphical representation of finite automata and its animation, and the definition of reactive finite automata. This library is described in the paper presented at FDPE'02.
4. HaGLRHaGLR is an implementation of Generalized LR parsing in Haskell. Apart from parsing with the GLR algorithm, it supports parsing with the LR algorithm, visualization of deterministic and non-deterministic finite automata, and export of ASTs in XML or ATerm format. As input, HaGLR accepts either plain context-free grammars, or SDF syntax definitions. The SDF front-end is implemented as an extension of the Sdf2Haskell? generator. HaGLR's functionality can also be accessed as library functions, available under the ContextFree? subdivision of the UMinho Haskell Libraries. HaGLR was implemented by João Fernandes and João Saraiva.
HaGLR is available from http://wiki.di.uminho.pt/twiki/bin/view/Research.PURe/HaGLR.
5. LRC
Lrc is a system for generating efficient incremental attribute evaluators. Lrc can be used to generate language based editors and other advanced interactive environments. Lrc can generate purely functional evaluators, for instance in Haskell. The functional evaluators can be deforested, sliced, strict, lazy. Additionally, for easy reading, a colored LaTeX? rendering of the generated functional attribute evaluator can be generated.
6. Sdf2Haskell?Sdf2Haskell? is a generator that takes an SDF grammar as input and produces support for GLR parsing and customizable pretty-printing. The SDF grammar specifies concrete syntax in a purely declarative fashion. From this grammar, Sdf2Haskell? generates a set of Haskell datatypes that define the corresponding abstract syntax. The Scannerless Generalized LR parser (SGLR) and associated tools can be used to produce abstract syntax trees which can be marshalled into corresponding Haskell values.
Recently, the functionality of Sdf2Haskell? has been extended with generation of pretty-print support. From the SDF grammar, a set of Haskell functions is generated that defines an pretty-printer that turns abstract syntax trees back into concrete expressions. The pretty-printer is updatable in the sense that its behaviour can be modified per-type by supplying appropriate functions.
Sdf2Haskell? is distributed as part of the Strafunski bundle for generic programming and language processing (http://www.cs.vu.nl/Strafunski). Sdf2Haskell? is being maintained by Joost Visser (Universidade do Minho, Portugal).
[Research Groups]
The Logic and Formal Methods group at the Informatics Department of the University of Minho, Braga, Portugal. http://www.di.uminho.pt/~glmf.
We are a group of about 12 staff members and various PhD? and MSc students. We have shared interest in formal methods and their application in areas such as data and code reverse and re-engineering, program understanding, and communication protocols. Haskell is our common language for teaching and research.
Haskell is used as first language in our graduate computers science education (section [Haskell in Education]). José Valença and José Barros are the authors of the first (and only) Portuguese book about Haskell, entitled "Fundamentos da Computação" (ISBN 972-674-318-4). Alcino Cunha has developed the Pointless library for pointfree programming in Haskell (section [Tools and libraries]), as well as the DrHylo? tool that transforms functions using explicit recursion into hylomorphisms. Supervised by José Nuno Oliveira, students Tiago Alves and Paulo Silva are developing the VooDooM tool, which transforms VDM datatype specifications into SQL datamodels and students João Ferreira and José Proença will soon start developing CPrelude.hs, a formal specification modelling tool generating Haskell from VDM-SL and CAMILA. João Saraiva is responsible for the implementation of the attribute system LRC, which generates (circular) Haskell programs. He is also the author of the HaLex? library and tool, which supports lexical analysis with Haskell. Joost Visser has developed Sdf2Haskell? , which generates GLR parsing and customizable pretty-printing support from SDF grammars, and which is distributed as part of the Strafunski bundle. Most tools and library modules develop by the group are organized in a single infrastructure, to facilitate reuse, which can be obtained as a single distribution under the name UMinho Haskell Libraries and Tools.
The group has recently started the 3-year project called Research.PURe which aims to apply formal methods to Program Understanding and Reverse Engineering. Haskell is used as implementation language, and various subprojects have been initiated, including Generic Program Slicing.
[Haskell in Education]
Haskell is heavily used in the undergraduate curricula at Minho. Both Computer Science and Systems Engineering students are taught two Programming courses with Haskell. Both programmes of studies fit the "functional-first" approach; the first course is thus a classic introduction to programming with Haskell, covering material up to inductive datatypes and basic monadic input/output. It is taught to 200 freshers every year. The second course, taught in the second year (when students have already been exposed to other programming paradigms), focusses on pointfree combinators, inductive recursion patterns, functors and monads; rudiments of program calculation are also covered. A Haskell-based course on grammars and parsing is taught in the third year, where the HaLeX? library is used to support the classes.
Additionally, in the Computer Science curriculum Haskell is used in a number of other courses covering Logic, Language Theory, and Semantics, both for illustrating concepts, and for programming assignments. Minho's 4th year course on Formal Methods (a 20 year-old course in the VDM tradition) is currently being restructured to integrate a system modelling tool based on Haskell and VooDooM. Finally, in the last academic year we ran an optional, project-oriented course on Advanced Functional Programming. Material covered here focusses mostly on existing libraries and tools for Haskell, such as YAMPA - functional reactive programming with arrows, the WASH library, the MAG system, the Strafunski library, etc. This course benefitted from visits by a number of well-known researchers in the field, including Ralf Laemmel and Peter Thiemann.
Combining Formal Methods and Functional Strategies Regarding the Reverse Engineering of Interactive Applications
João Carlos Silva
Graphical user interfaces (GUIs) make software easy to use by providing the user with visual controls. Therefore, correctness of GUI's code is essential to the correct execution of the overall software. Models can help in the evaluation of interactive applications by allowing designers to concentrate on its more important aspects. This paper describes our approach to reverse engineer an abstract model of a user interface directly from the GUI's legacy code. We also present results from a case study. These results are encouraging and give evidence that the goal of reverse engineering user interfaces can be met with more work on this technique.
The Quality Economics of Defect-Detection Techniques
Stefan Wagner, Software & Systems Engineering, Technische Universitaet Muenchen, Institut fuer Informatik
Analytical software quality assurance (SQA) constitutes a significant part of the total development costs of a typical software system. Typical estimates say that up to 50\% of the costs can be attributed to defect detection and removal. Hence, this is a promising area for cost-optimisations. The main question in that context is then how to use those different techniques in a cost-optimal way. In detail this boils down to the questions to use (1) which techniques, (2) in which order, and (3) with what effort. This talk describes an analytical and stochastic model of the economics of analytical SQA that can be used to analyse and answer these questions. The practical application is shown on the example of a case study on model-based testing in the automotive domain.
The end of the Research.PURe project is approaching. We will be able to look back at a successful project with lots of interesting deliverables. But now it becomes urgent to reflect on what comes after Research.PURe. A deadline for new FCT proposals is July 31. We will initiate discussion about concrete ideas for such a follow-up project.
(1) Prototype Implementation of an Algebra of Components in Haskell
Jácome Cunha
The starting point to this project are state-based systems modeled as components, i.e, "black boxes" that have "buttons" or "ports" to communicate with the whole system. A list of operators to connect these components is given. A possible way to implement components as coalgebras in Haskell is shown. Finally, a tool to generate a component from a state-based system definition is implemented.
This communication is a follow up of [1]. We show how to model some of the key concepts of VDM++ in Haskell. Classes, objects, operations and inheritance are encoded based on the recently developed OOHaskell library.
[1] Camila Revival: VDM meets Haskell, Joost Visser, J.N. Oliveira, L.S. Barbosa, J.F. Ferreira, and A. Mendes. Overture Workshop, colocated with Formal Methods 2005.
This communication is an attempt to apply the calculational style underlying the so-called Bird-Meertens formalism to generalised coinduction, as defined in F. Bartels' thesis. In particular, equational properties of such generic recursion scheme are given, relying on its universal characterisation. We also show how corresponding calculational kits for particular instances of the general coinduction are derived by specialisation.
We present a local graph-rewriting system capable of deciding equality on a fragment of the language of point-free expressions. The fragment under consideration is quite limited since it does not includes exponentials. Nevertheless, it constitutes a non-trivial exercise due to interactions between additive and multiplicative laws.
We propose a novel, comonadic approach to dataflow (stream-based) computation. This is based on the observation that both general and causal stream functions can be characterized as coKleisli arrows of comonads and on the intuition that comonads in general must be a good means to structure context-dependent computation. In particular, we develop a generic comonadic interpreter of languages for context-dependent computation and instantiate it for stream-based computation. We also discuss distributive laws of a comonad over a monad as a means to structure combinations of effectful and context-dependent computation. We apply the latter to analyse clocked dataflow (partial streams based) computation.
Joint work with Varmo Vene, University of Tartu. Appeared in Proc of APLAS 2005.
We define a strongly-typed model of relational databases and operations on them. In this model, table meta-data is represented by type-level entities that guard the semantic correctness of all database operations at compile time. The model relies on type-class bounded and parametric polymorphism and we demonstrate its encoding in the functional programming language Haskell. Apart from the standard relational database operations, such as selection and joins, we formalize functional dependencies and normalization. We show how functional dependency information can be represented at the type level, and can be transported through operations from argument types to result types. The model can be used for static query checking, but also as the basis for a formal, calculational approach to database design, programming, and migration. The model is available as sub-library of the UMinho Haskell Libraries, and goes under the name of CoddFish.
Functional programming provides different programming styles for programmers to write their programs in. The differences are even more explicit under a lazy evaluation model, under which a computation of a value is only triggered upon its need. When facing the challenge of implementing solutions for multiple traversals algorithm problems, the functional programmer often tends to assume himself as the decision maker of all the implementation details: how many traversals to define, in which order to schedule them, which intermediate structures to define and traverse, just to name some. Another sub-paradigm is available, though. Given the proper will and sufficient practice, multiple traversal algorithms are possible to be implemented as lazy circular programs, where some of the programming work is handed to the lazy machinery.In this talk I will present a calculational rule to convert multiple traversal programs into single-pass circular ones. Feedback is more than expected, it is wanted!
A BIC was recently assigned to Zé Pedro Correia. Its subject is to develop a tool to manipulate point-free expressions, according to transformation laws, in order to construct a point-free proof. This talk will serve to introduce this project to the Research.PURe group, presenting the work done so far and the work to do. We also expect to collect some opinions on the general expected "behaviour" of the tool.
We constructed a tool, called VooDooM, which converts datatypes in VDM-SL into SQL relational data models. The conversion involves transformation of algebraic types to maps and products, and pointer introduction. The conversion is specified as a theory of refinement by calculation. The implementation technology is strategic term rewriting in Haskell, as supported by the Strafunski bundle. Due to these choices of theory and technology, the road from theory to practise is straightforward.
Na programação funcional existem vários estilos de programação, não havendo consenso quanto a qual será o melhor. Dois estilos opostos são, por exemplo, pointfree e pointwise, que se distinguem principalmente por no primeiro serem utilizadas variáveis e no segundo não. No trabalho foi introduzida uma possível descrição de expressões em pointfree e em pointwise, de tal forma que estas fossem o mais simples possível. Depois foi introduzido um processo que permite converter expressões entre estes dois tipos. Foram também consideradas outras linguagens pointwise que podem ser convertidas para o tipo pointwise originalmente criado. O principal objectivo foi tornar possível a transição de código pointwise para pointfree, utilizando bases teóricas e com a garantia de que não sejam introduzidos erros no processo de conversão.
PURe CAMILA: A System for Software Development using Formal Methods
João F. Ferreira
This work consists in the first steps for the re-implementation of CAMILA, which is a software development environment intended to promote the use of formal methods in industrial software environments. The new CAMILA, also called Research.PURe CAMILA, is written in Haskell and makes use of monadic programming. A small prototype interpreter was created, but the purpose of this work is to study the concepts behind such a tool, such as datatype invariants and partial functions.
In this paper, we present a collection of aspect-oriented refactorings covering both the extraction of aspects from object-oriented legacy code and the subsequent tidying up of the resulting aspects. In some cases, this tidying up entails the replacement of the original implementation with a different, centralized design, made possible by modularization. The collection of refactorings includes the extraction of common code in various aspects into abstract superaspects. We review the traditional object-oriented code smells in the light of aspect-orientation and propose some new smells for the detection of crosscutting concerns. In addition, we propose a new code smell that is specific to aspects.
Miguel Vilaça will introduce the topic of designing a visual language for pointfree programming. After this, we will exchange ideas about how to approach this problem.
In the context of Joost Visser's Spreadsheets under Scrutiny talk, I have been looking at refinement laws for spreadsheet normalization. Back to good-old `functional dependency theory', D. Maier's book etc, I ended up by rephrasing of the standard theory using the binary relation pointfree calculus. It turns out that the theory becomes simpler and more general, thanks to the calculus of 'simplicity' and coreflexivity. This research also shows the effectiveness of the binary relation calculus in «explaining» and reasoning about the n-ary relation calculus «à la Codd».
Grammars are to parser generators what programming languages are to compilers. Although parsing is a subset of a well studied area like compilers, grammars were always looked upon as "the ugly duckling". In this presentation I will propose a methodology for developing grammars using the SDF (Syntax Definition Formalism) inspired in Extreme Programming. This methodology was used to develop a grammar for ISO VDM-SL, one of the most common languages used for formal specification. The grammar is available from: VooDooMFront.
Damijan Rebernak from Maribor University, Slovenia, will present a talk on grammar-based tools. NOTE: The talk will start at 12:00, instead of the usual hour of 11:00.
In the Pure Workhsop last Sptember a limitation of the Hylo-shift law for program calculation was identified, and a possible way of solving it was then discussed. In this talk I will present my current understanding of how a generalized version of the law can be formalized.
In this talk we will show how Haskell can be used to process spreadsheets. We will demonstrate a prototype that takes an excell workbook as input, converts it to gnumeric's xml representation of spreadsheets with formulas, reads and parses the xml representation into a strongly type set of haskell datatypes, and finally computes and visualizes the spreadsheet data flow graph. The audience will be invited to suggest interesting spreadsheet analyses and transformations that might be implemented with this infrastructure.
This is a sneak preview of the student presentation João will give at the Summer School on Advanced Functional Programming (Tartu, 21 august, 2004). GLR parsing is a generalization of LR parsing where ambiguous grammars do not lead to parse errors, but to several parsers working in parallel. We have implemented GLR in Haskell relying on lazy evaluation and incremental computation to improve its performance and approach closer to the original imperative formulation of the algorithm.
The data models of most legacy software systems are not explicitly defined. Instead, they are encoded in the program source code. Using a mixture of program understanding techniques it is possible to (partly) reconstruct these models. In this talk we provide details of a reverse engineering project carried out at the Software Improvement Group. In this project, the software portfolio of a large multinational bank, consisting of many million lines of Cobol code, was analyzed. Both hierarchical databases (IMS) and relational ones (DB2) are used in this portfolio. We will survey the program understanding techniques used, and detail the particular challenges posed by the size and heterogeneity of the analyzed portfolio.
Datatype invariants are a significant part of the business logic which is at the heart of any commercial software application. However, invariants are hard to maintain consistent and their formal verification requires costly «invent and verify» procedures, most often neglected throughout the development life-cycle. We sketch a basis for a calculational approach to maintaining invariants based on a «correct by construction» development principle. We propose that invariants take the place of data-types in the diagrams that describe computations and use weakest liberal preconditions to type the arrows in such diagrams. All our reasoning is carried out in the relational calculus structured by Galois connections.
Parser combinators elegantly and concisely model generalised LL parsers in a purely functional language. They nicely illustrate the concepts of higher-order functions, polymorphic functions and lazy evaluation. Indeed, parser combinators are often presented as "the" motivating example for functional programming. Generalised LL, however, has an important drawback: it does not handle (direct nor indirect) left recursive context-free grammars. In a different context, the (non-functional) parsing community has been doing a considerable amount of work on generalised LR parsing. Such parsers handle virtually any context-free grammar. Surprisingly, no work has been done on generalised LR by the functional prog. community. In this talk, I will present a concise (100 lines!), elegant and efficient implementation of an incremental generalised LR parser generator/interpreter in Haskell. Such parsers rely heavily on lazy evaluation. Incremental evaluation is obtained via function memoisation. I will present the HaGlr tool: a prototype implementation of our generalised LR parser generator. The profiling of some (toy) examples will be discussed.
The basic motivation of component based development is to replace conventional programming by the composition and configuration of reusable off-the-shelf units externally coordinated, through a network of connecting devices, to achieve a common goal. This work introduces a new relational model for connectors of software components. The proposed model adopts a coordination point of view in order to deal with components temporal and spatial decoupling and, therefore, to provide support for looser levels of inter-component dependency and effective external control.
A Unified Approach for the Integration of Distributed Heterogeneous Software Components
Barrett Bryant
A framework is proposed for assembling software systems from distributed heterogeneous components. For the successful deployment of such a software system, it is necessary that its realization not only meets the functional requirements but also non-functional requirements such as Quality of Service (QoS) criteria. The approach described is based on the notions of a meta-component model called the Unified Meta Model (UMM), a generative domain model, and specification of appropriate QoS parameters. A formal specification based on Two-Level Grammar is used to represent these notions in a tightly integrated way so that QoS becomes a part of the generative domain model. A simple case study is described in the context of this framework.
In this talk, I will give a brief overview of Haskell software development around the world and I will present a light-weight infrastructure to support such development by us. Among other things, I will talk about development tools such as Haddock, QuickCheck, HUnit, and GHood. I will point out some nice development projects that seem relevant to the Research.PURe project, such as the refactoring project in Kent.
Functional programs are particularly well suited to formal manipulation by equational reasoning. In this setting, it is straightforward to use calculational methods for program transformation. Well-known transformation techniques, like tupling or the introduction of accumulating parameters, can be implemented using calculation through the use of the fusion (or promotion) strategy. In this paper we revisit this transformation method, but, unlike most of the previous work on this subject, we adhere to a pure point-free calculus that emphasizes the advantages of equational reasoning. We focus on the accumulation strategy initially proposed by Bird, where the transformed programs are seen as higher-order folds calculated systematically from a specification. The machinery of the calculus is expanded with higher-order point-free operators that simplify the calculations. A substantial number of examples (both classic and new) are fully developed, and we introduce several shortcut optimization rules that capture typical transformation patterns.
Functional transposition is a technique for converting relations into functions aimed at developing the relational algebra via the algebra of functions. This talk attempts to develop a basis for generic transposition. Two well-known instances of the construction are considered, one applicable to any relation and the other applicable to simple relations only. Our illustration of the usefulness of the generic transpose takes advantage of the free theorem of a polymorphic function. We show how to derive laws of relational combinators as free theorems of their transposes. Finally, we relate the topic of functional transposition with the hash-table technique for data representation.
Members of the Research.PURe team seem to see in sorting algorithms a never-ending source of inspiration. In this session JoseBarros and ManuelBernardoBarbosa will explain why they think program-understanding can help optimize sorting algorithms, and JorgeSousaPinto will discuss how all major functional sorting algorithms can be derived from insertion sort.
We will explain the basics of collaborative web editing with Wiki. We will discuss the way we have organized our local Wiki and invite you to contribute to it. Finally we will exchange ideas about how to use the Wiki for our research and education.
March, 25 The lambda-coinduction by calculation stuff was presented today in Wien by AlexandraSilva as a short communication to CMCS'06.
March, 24 A paper on Slicing by Calculation (NunoRodrigues and LuisSoaresBarbosa) and another one on Generic Process Algebra (Paula Ribeiro, MarcoAntonioBarbosa and LuisSoaresBarbosa) accepted for SBLP'06 (acceptance rate: 35%).
March, 20 Research.PURe Year 2 Progress Report was released. Once again the project performance was very good: 4 journal papers (1 was expected), 9 conference papers (5 expected), 1PhD thesis and 2 MSc dissertations.
March, 9 A technical report by Alcino Cunha, José Nuno Oliveira, and Personal.Joost Visser entitled Type-safe Two-level Data Transformation is available here.
Jan, 23 A paper by Personal.Joost Visser entitled Structure Metrics for XML Schema will be presented at XATA2006.
Jan, 6 The paper by by AlcinoCunha, JorgeSousaPinto, and JoseProenca presented in September at the IFL'05 Workshop has been accepted for publication in the Revised Papers (Springer LNCS).
2005
Dec, 9 A paper by Miguel Cruz, LuisSoaresBarbosa and JoseNunoOliveira, entitled From Algebras to Objects: Generation and Composition was published today in the Journal of Universal Computer Science (vol 11 (10)).
Dec, 3 A paper by Personal.Joost Visser entitled Matching Objects without Language Extension was accepted for publication in the Journal of Object Technology.
Nov, 14NunoRodrigues participated in the Schloss Dagstuhl Seminar 05451 on "Beyond Program Slicing", presenting a
paper on "Calculating Functional Slices". His group received the Best Presentation Award.
Sep, 19 Paper accepted at FACS'05 on Component Identification Through Program Slicing (by NunoRodrigues and LuisSoaresBarbosa).
August 15 II Research.PURe Workshop scheduled for 11-12 October, 2005. Invited speaker: Jeremy Gibbons (Oxford)
July 20 Paper accepted at ICTAC 2005 on Refinement of Software Architectures (by Sun Meng, LuisSoaresBarbosa and Zhang Naixiao).
April 9 Paper accepted at FM 2005 on VooDooM (by TiagoAlves, PauloSilva, JoseNunoOliveira, and JoostVisser).
April 5 The first distribution of the UMinho Haskell Software was released.
Mar 21 The PUReCafe slot will open each Tuesday on 12:00 (was 11:00).
Jan 17 Good News: The expected number of publications in the original Research.PURe proposal for
the fisrt year has been largely surpassed (5 expected vs 11 published + more 5 accepted).
More details on the project performance can be read on the Y1 Progress Report.
2004
Sep 27 Various tools from PUReSoftware are now available online.
Sep 26 The PUReCafe slot was moved to Tuesday's between 11:00 and 13:00.
Sep 20 The EVENTS topic was updated with information on the workshop. Authors: please upload your slides!
Sep 7 2nd Announcement and Programme: First Project Workshop, 13-14 September 2004
Aug 25 Research.PURe paper accepted at ICTAC2004 on coalgebraic models for software connectors (by MarcoAntonioBarbosa and LuisSoaresBarbosa).
July 26 Call for Participation: First Project Workshop, 13-14 September 2004
June 17 Matthijs Kuiper, main developer of the LRC attribute grammar system, will be visiting the department in the week of June 21-25.
June 4 Another date for all Research.PURe people: First Project Workshop scheduled for 13-14 September. Alberto Pardo (Uruguay) is an invited speaker.
June 4 First Research.PURe Seminar on Algebras of Program Construction by R. Backhouse, 21-22 June
June 3 Research.PURe paper accepted at CTCS2004 on the semantics of UML components (by LuisSoaresBarbosa, Sun Meng, B. Aichernig and Zhang Naixiao).
On the Specification of a Component Repository, Rodrigues, N. and Barbosa, L., FACS'03 (Int. Workshop on Formal Aspects of Component Software), FME, Pisa. September, 2003. (pdf)
Automatic Visualization of Recursion Trees: a Case Study on Generic Programming, Cunha, A., WFLP'03 (12th International Workshop on Functional and (Constraint) Logic Programming). In volume 86.3 of ENTCS: Selected papers of WFLP'03. 2003. (pdf)
Towards a Relational Model for Component Interconnection, Barbosa, M. A. and Barbosa, L. SBLP'04, Niteroi. May, 2004.
On Refinement of Generic Software Components, Meng, S. and Barbosa, L., AMAST'04 (10th Int. Conf. on Algebraic Methods and Software Technology), Stirling, August, 2004 (Best Student Co-authored Paper Award). Springer LNCS 3116 (pag. 506 - 520).
Transposing Relations: from Maybe Functions to Hash Tables, Oliveira J.N and Rodrigues C.J., MPC'04 (Int. Conf. on the Mathematics of Program Construction), Stirling, August 2004, Springer LNCS 3125 (pag. 334-356).
A Coalgebraic Semantic Framework for Component Based Development in UML, Meng, S. and Aichernig, B. and Barbosa, L. and Naixiao, Z., CTCS'04 (Int. Conf. on Category Theory and Computer Science), Copenhagen. August, 2004 (to appear ENTCS)
Design, Implementation and Animation of Spreadsheets in the Lrc System, João Saraiva, FoS'04 (Int. Workshop on Foundations of Spreadsheets), Rome, Italy, September, 2004 (to appear ENTCS) http://www.di.uminho.pt/~jas/Research/Papers/FOS04/divs.ps.gz
On Semantics and Refinement of Statecharts: A Coalgebraic View, Meng, S. and Naixiao, Z and Barbosa, L., II SEFM (2nd IEEE International Conference on Software Engineering and Formal Methods), Beijing. September, 2004. IEEE Computer Society Press.
Bounded Version Vectors, Almeida J. B. and Almeida P. S. and Baquero C., Proceedings of DISC 2004 (18th International Symposium on Distributed Computing), Springer-Verlag LNCS 3274 (pag. 102 - 116). October, 2004.
Specifying Software Connectors, Barbosa, M. A. and Barbosa, L. ICTAC'04 (to appear in Springer LNCS), Guyang, China, September, 2004.
Functional Programming and Program Transformation with Interaction Nets, Mackie I., Pinto J.S, Vilaça M. In preliminary proceedings of International Symposium on Logic-based Program Synthesis and Transformation (LOPSTR 2005).
A Framework for Point-free Program Transformation, Alcino Cunha, Jorge Sousa Pinto and José Proença. In Revised Proceedings of the 17th International Workshop on Implementation and Application of Functional Languages (IFL'05). To appear in Springer LNCS.
Structure Metrics for XML Schema, Joost Visser. Proceedings of XATA2006.
A Local Graph-rewriting System for Deciding Equality in Sum-product Theories, José Bacelar Almeida, Jorge Sousa Pinto, and Miguel Vilaça. In Proceedings of the Third Workshop on Term Graph Rewriting (TERMGRAPH 2006), Vol. 176(1) Electronic Notes in Theoretical Computer Science, pags. 139-163, 2007.
Strongly Typed Rewriting For Coupled Software Transformation, Alcino Cunha, Joost Visser. In Proceedings of RULE 2006, ENTCS, to appear.
Strong Types for Relational Databases, Alexandra Silva and Joost Visser. In Proceedings of Haskell Workshop 2006, to appear.
Publications (Journal Papers and Book Chapters)
A Relational Model for Component Interconnection, Barbosa, M. A. and Barbosa, L., Jour. Universal Computer Science, 10 (7), pag. 808-823, 2004.
(accepted) On the Semantics of Componentware: A Coalgebraic Perspective, Barbosa, L. and Meng, S. and Aichernig, B. and Rodrigues, N., chapter in "Mathematical Frameworks for Component Software - Models for Analysis and Synthesis", Jifeng He and Zhiming Liu (eds), Review Volume in the Series on Component-Based Development, World Scientific. 2004.
(accepted) Components as Coalgebras: the Refinement Dimension, Sun Meng and Barbosa, L., Theor. Computer Science, Elsevier, 2004.
Point-free Program Transformation, Cunha, A. and Pinto, J.S., Fundamenta Informaticae Volume 66, Number 4 (Special Issue on Program Transformation), April-May 2005, IOS Press, 2005.
Object Matching without Language Extension, Joost Visser, Journal of Object Technology, accepted for publication in the Nov/Dec 2006 issue.
Generalized LR Parsing in Haskell, João Fernandes, DI-Research.PURe-04.11.01, November 2004. (pdf)
Conversão de Código Pointwise para Código Pointfree, José Vilaça, DI-Research.PURe-04.11.02, November 2004. (pdf)
Functional dependency theory made 'simpler', J.N. Oliveira, DI-Research.PURe-05.01.01, January 2005. (pdf)
Tranformações pointwise - point-free, José Proença, DI-Research.PURe-05.02.01, February 2005. (pdf)
Development of an Industrial Strength Grammar for VDM, Tiago Alves and Joost Visser, DI-Research.PURe-05.04.29, April 2005. (pdf)
Metrication of SDF Grammars, Tiago Alves and Joost Visser, DI-Research.PURe-05.05.01, May 2005. (pdf)
Functional Programming and Program Transformation with Interaction Nets, Ian Mackie, Jorge Sousa Pinto and Miguel Vilaça, DI-Research.PURe-05.05.02, May 2005 (pdf)
Down with Variables, Alcino Cunha, Jorge Sousa Pinto, and José Proença, DI-Research.PURe-05.06.01, June 2005 (pdf)
Point-free Simplification, José Proença, DI-Research.PURe-05.08.01, August 2005. (pdf)
ProveIt - An interactive point-free proof editor, José Pedro Correia, DI-Research.PURe-05.08.02, August 2005. (pdf)
A Local Graph-rewriting System for Deciding Equality in Sum-product Theories, José Bacelar Almeida, Jorge Sousa Pinto, and Miguel Vilaça. DI-Research.PURe-06.02.01, February 2006 (revised in June 2006). (pdf)
Type-safe Two-level Data Transformations -- with appendix on derecursivation and dynamic typing, Alcino Cunha, José Nuno Oliveira, Joost Visser. DI-Research.PURe-06.03.01, March 2006. (pdf)
A Tool for Programming with Interaction Nets, José Bacelar Almeida, Jorge Sousa Pinto and Miguel Vilaça. DI-Research.PURe-06.04.01, April 2006. (pdf)
Deriving Sorting Algorithms, José Bacelar Almeida, Jorge Sousa Pinto. DI-Research.PURe-06.04.02, April 2006. (pdf)
Report Publication
Next report number: DI-Research.PURe-06.04.03 (please update on uploading a new report: YY.MM.nn, nn being sequential inside each month)
The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that is being developed in the context of various research and educational projects. The objective is to enable use and reuse of software accross project boundaries. In particular, software developed in the context of the Research.PURe Project, is collected into the UMS repository.
The UMS repository is roughly partitioned into two parts:
Libraries: a hierarchical library of reusable modules.
Tools: a collection of tools.
The libraries offer reusable functionality. Each tool bundles part of the library functionality behind an interactive or command-line interface.
If you want to contribute, please consult UsingCVS.
The UMinho Haskell Libraries
The UMinho Haskell Libraries are located in the libraries subdirectory. The modules included in the libraries cover a wide range of functionality, for instance:
Data.Relation: Representation and operations on relations. A special case of relations are graphs. The operations include graph chopping and slicing, strong connected component analysis, graphs metrics, and more.
Language.Gnumeric: Support for analysis and manipulation of spreadsheets.
Language.Java: Support for analysis and manipulation of Java programs.
Pointless: Support for pointfree programming.
Camila: Support for VDM like concepts, such as data type invariants, pre- and post-conditions, and more.
For a complete overview, see the online API documentation for version 1.0, generated with Haddock. In the distribution, the API documentation can be found in the subdirectory libraries/documentation.
The libraries subdirectory contains a Makefile that allows you to easily do various things, among which:
make ghc
compile all library modules with GHC
make ghci
load all library modules into GHCi
make haddock
generate library documentation with Haddock
make dist
generate a distribution of the library
make hunit
run HUnit on all test modules
make quickCheck
run quickCheck on all library modules
make ghood
generate GHood applets
If you want to operate on just a part of the library, you can do that by overriding the Makefile's top
variable, for instance as follows:
make top=Data/Relation ghci
And likewise for any other target. Consult the Makefile for other variables that can be overridden.
The UMinho Haskell Tools
Several tools are included in the UMS distributions, among which:
Pointless Haskell is library for point-free programming with recursion patterns defined as hylomorphisms. It is part of the UMinho Haskell Libraries that are being developed in the Research.PURe project. The core of the library is described in the following paper.
It also allows the visualization of the intermediate data structure of the hylomorphisms with GHood. This feature toghether with the DrHylo tool allows us to easily visualize recursion trees of Haskell functions. We first implemented this ideas using Generic Haskell, as presented in WFLP'03. We now take a different approach to genericity based on Personal/Alcino.PolyP.
Point-free definitions of uncurried versions of the basic combinators.
Pointless.Isomorphisms
Auxiliary isomorphism definitions.
Pointless.Functors
Definition of functors, generic maps, and sum-of-products representation.
Pointless.RecursionPatterns
Definition of the typical recursion as hylomorphisms.
Pointless.Observe.Functors
Definition of generic observations.
Pointless.Observe.RecursionPatterns
Recursion patterns with observation of intermediate data structures.
Pointless.Examples.Examples
Lots of examples.
Debug.Observe
Slightly modified GHood library.
Usage
For the moment there is no documentation, but by reading the papers and looking at examples you should be able to learn it by yourself. It was only tested on GHC. I think that it should be easy to use it under Hugs.
Please send feedback to alcino@di.uminho.pt.
Tool for deriving hylomorphisms from a restricted Haskell syntax. It is based on the algorithm first presented in the paper Deriving Structural Hylomorphisms From Recursive Definitions at ICFP'96 by Hu, Iwasaki, and Takeichi.
This is a project where I, José Proença, worked on since April until October 2005. It was supervised by Jorge Sousa Pinto and Alcino Cunha, who supported and helped me during this time. The proposal is explained in more detailed in here. The results can be found in my internship report, here.
The project consists on two parts:
Definition of two refactorings -- the conversion from point-wise to pointfree and the removal of guards;
Automatic simplification and transformation of pointfree expressions.
Refactorings in HaRe
In the begining of the project, I spent two weeks in Canterbury developing two refactorings to be part of HaRe:
A snapshot of the source code where these transformations are applied can be found here.
There are also some examples that can be found in the following links:
Allows for the automatic simplification and some program transformation of Haskell code, written in a point-free style. The technical report is available here. The SimpliFree tool is now available in the Uminho Haskell Libraries, that can be downloaded from the CVS repository.
This tool uses Haskell pattern matching to apply rules, by creating an auxiliary file with the functions where the strategies, rules and the pointfree terms are defined. In spite of the fact that this approach meant to be simpler than most approaches where a pattern matching algorithm is defined, the definitions of functions that apply a rule were more complex than expected.
In September, this tool, together with the DrHylo tool and the Pointless library, were presented in IFL'05 workshop.
The presentation "A Framework for Point-free Program Transformation", shown in this workshop, can be found here.
The SimpliFree tool was also presented in the PURe Workshop 2005. The slides can be found here.
In a situation in which the only quality certificate of the running software artifact still is life-cycle endurance, customers and software producers are little prepared to modify or improve running code. However, faced with so risky a dependence on legacy software, managers are more and more prepared to spend resources to increase confidence on - i.e. the level of understanding of - their code.
As a research area, program understanding affiliates to reverse engineering, understood as the analysis of a system in order to identify components and intended behaviour to create higher level abstractions of the system.
If forward software engineering can today be regarded as a lost opportunity for formal methods (with notable exceptions in areas such as safety-critical and dependable computing), its converse still looks a promising area for their application. This is due to the complexity of reverse engineering problems and exponential costs involved.
In such a setting, this project intends to develop calculi for program understanding and reverse engineering, building on the formal techniques developed by academics for the production of fresh, high quality software. One of its fundamental goals is to show that such techniques, eventually merged with other, informal program maintenance and debugging procedures, will see the light of (industrial) success in their reverse application to pre-existing code.
The project addresses the areas of program reengineering, classification and refinement. The envisaged notion of a `program' is broad enough to include typical data-processing applications, real-time algorithms or component-based services. As an increasing number of systems are based on the cooperation of distributed, heterogeneous components organised into open software architectures, a particular emphasis is placed on the extension of classical techniques to the classification and reeginering of coordination middlewares. In each of these areas the project aims to develop specific techniques and calculi which, based on sound mathematical foundations, are scalable to the industrial practice and easily applicable by the working software engineer.
SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non-terminals, productions, and disambiguation constructs, McCabe's cyclometric complexity, and structure metrics such as tree impurity and normalized count of grammar levels.
The metrics implemented by SdfMetz are explained and illustrated in:
Tiago Alves and Joost Visser, Metrication of SDF Grammars. Technical Report, DI-Research.PURe-05.05.01, Departamento de Informática, Universidade do Minho, May 2005. pdf
Fig 1: Scatterplot of non-terminal count versus Halstead size metrics.
This technical report also shows metric values for 27 non-trivial grammars, and some discussion of the interpretation of this data. Some exerpts from the report are included below. A companion tool SdfCoverage, for measuring grammar coverage is also mentioned in the report.
SdfMetz is intended to be an instrument for Grammar Engineering. An overview of research into grammar engineering can be found in:
P. Klint and R. Lämmel and C. Verhoef, Towards an engineering discipline for grammarware, link.
In particular, SdfMetz is inspired by
James F. Power and Brian A. Malloy, A metrics suite for grammar-based software, link.
We have adapted their suite of metrics to the SDF grammar notation, and extened it with a few SDF-specific metrics. Also, the SdfMetz tool supports generation of immediate and transitive successor graphs from SDF grammars. For details, see the technical report Metrication of SDF grammars.
SDF stands for Syntax Definition Formalism. It is a purely declarative (no semantic actions) and modular grammar notations which is supported by Generalized LR Parsing. For information and resources regarding SDF, see:
The initial motivation for the development of the SdfMetz tool came from a grammar development project where an SDF grammar for the VDM-SL language was recovered from an ISO reference manual. A description of the use of SdfMetz for monitoring that grammar development process can be found in:
Tiago Alves and Joost Visser, Grammar-centered Development of VDM Support. In proceedings of the Overture Workshop, colocated with Formal Methods 2005. Technical Report of the University of Newcastle, to appear, 2005. pdf
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. pdf
The deliverable of that project, a VDM-SL front-end, can be found on the VooDooMFront web page.
Features
Fig 2: Immediate successor graph of a fragment of the VDM-SL grammar.
Fig 3: Transitive successor graph of the same fragment of the VDM-SL grammar.
SdfMetz is a command line tool. For details about its usage, type SdfMetz -h at the command line prompt.
Input
SdfMetz accepts one of more SDF grammar files as input.
Alternatively, SdfMetz accepts grammars in Semantic Designs' DMS grammar notation.
Output
The metric values computed by SdfMetz can be exported as a nicely formatted textual report, or as comma-separated-value files, for easy import into e.g. Excel or SPSS.
SdfMetz calculates immediate and transitive successor graphs to compute structure metrics. These graphs can also be exported, in the dot format of AT&T's GraphViz'.
In addition, SdfMetz can export the non-singleton levels of the input grammars. These are groups of non-terminals that are mutually reachable from each other in the grammar's successor graph.
Computed metrics
The suite of metrics computed by SdfMetz is defined and explained in the technical report Metrication of SDF grammars. They include counters for non-terminals, terminals, productions, and disambiguations constructs, McCabe's cyclometeric complexity, and structure metrics such as tree impurity and normalized count of levels.
A grammar comparison experiment
As an initial experimant in grammar metrication, we have applied SdfMetz to collect metrics data for a range of grammars from various origins. Full details about this experiment can be found in the Section Data Collection in:
Tiago Alves and Joost Visser, Metrication of SDF Grammars. Technical Report, DI-Research.PURe-05.05.01, Departamento de Informática, Universidade do Minho, May 2005. pdf
Sampled grammars
The sampled grammars include 18 SDF grammars for languages such as Yacc, BibTex, Fortran, Toolbus, Stratego, SDF itself, Java, SDL, C, Cobol, DB2, PL/SQL, VDM-SL, and VB.Net. These grammars were obtained from the following sources:
sfi - Grammars freely available in the Strafunski bundle
In the report, metrics calculated by us are presented side by side with those of four BNF grammars from the paper A metrics suite for grammar-based software of Power and Malloy.
Raw data
The technical report presents the collected metrics data in a series of tables, one for each category of metrics. The raw data of the experiment is available upon request in a single comma-separated-value file.
A grammar monitoring experiment
Fig 4: Plot of three grammar metrics for 48 subsequent development versions.
The initial motivation for the development of the SdfMetz tool came from a grammar development project where an SDF grammar for the VDM-SL language was recovered from an ISO reference manual. A description of the use of SdfMetz for monitoring that grammar development process can be found in:
Tiago Alves and Joost Visser, Grammar-centered Development of VDM Support. In proceedings of the Overture Workshop, colocated with Formal Methods 2005. Technical Report of the University of Newcastle, to appear, 2005. pdf
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. pdf
The deliverable of that project, a VDM-SL front-end, can be found on the VooDooMFront web page.
Implementation
The SdfMetz tool was implemented in the functional programming language Haskell using the Strafunski bundle for generic traversal support.
The tool was developed using a grammar-centered approach, where various kinds of functionality were automatically generated from a concrete syntax definition of the SDF language (the SDF language specified in SDF). The parser was automatically generated with sdf2table, from the SDF bundle. The Haskell support for representing, and pretty-printing abstract syntax trees (ASTs) was automatically generated with Sdf2Haskell, from the Strafunski bundle. AST traversal and marshalling support was generated with the Strafunski-aware DrIFT tool.
The reusable functionality of SdfMetz has been organized as modules of the UMinho Haskell Libraries. The structure metrics and underlying graph algorithms have been implemented on a generic graph representation, available from these same libraries.
Download
The SdfMetz tool (version 1.1) is available for download in a self-contained distribution. (download)
As alternative, it can also be obtained as part of the UMinho Haskell Libraries & Tools.
Future work
Apart from adding more metrics to the repertoire of SdfMetz, we intend to do the following:
Add front-ends for Yacc and ANTLR grammars
Collect more grammars for experimentation
Perform more comprehensive statistical analysis on the collected data
The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering techniques to spreadsheets.
Spreadsheet tools can be viewed as programming environments for
non-professional programmers. These so-called ''end-user'' programmers include teachers, secretaries, physicists, biologists, accountants, managers, consultants. For all these people, who are not employed or trained as programmers, spreadsheets are more often than not the programming environment of choice.
In fact, end-user programmers vastly outnumber professional programmers. By some estimates, the number of end-user programmers in the U.S. alone is expected to reach 55 million by 2005, as compared to only 2.75 million professional programmers. Through the efforts of these people, huge numbers of large and often complex spreadsheets are created and maintained every day in all companies and public institutes around the world. For these organizations, spreadsheets represent business-critical assets with significant economic value.
Spreadsheets, like any other program, can unfortunately easily turn from asset into liability. Development, maintenance, and extension of spreadsheets is notoriously error-prone. It is difficult to grasp the logic encoded in a spreadsheet, especially when it is large and developed by others. It is difficult to test spreadsheets, to assess their quality, and to validate their correctness. In this sense, a legacy problem exists with respect to spreadsheets as much, or perhaps even more, as with respect to conventional programs.
This observation leads to the suggestion that techniques for program understanding and reverse engineering, could be likewise applied, in adapted form, to spreadsheets. Just as they are useful for dealing with legacy software in the conventional sense, so they could be useful for dealing with spreadsheet legacy.
In fact, spreadsheets, when viewed as programming language, can be characterized as a particularly low-level one. Their language of cell references and formulas offers only low-level expressiveness compared to regular programming languages. They offer no support for abstraction, encapsulation, or structured programming. For this reason, it is fair to state that spreadsheets could benefit even more from program understanding and reverse engineering techniques than conventional programs.
In this project, Martin Erwig, Robin Abraham and Margaret Burnett defined a unit system for spreadsheets that allows to reason about the correctness of formulas in concrete terms. The fulcral point of this project is the high flexibility of the unit system developed, both in terms of error reporting and reasoning rules, that increases the possibility of a high acceptance among end users.
Selected Publications
How to Communicate Unit Error Messages in Spreadsheets, Robin Abraham and Martin Erwig, 1st Workshop on End-User Software Engineering, 52-56, 2005 (pdf)
Header and Unit Inference for Spreadsheets Through Spatial Analyses, Robin Abraham and Martin Erwig, IEEE Int. Symp. on Visual Languages and Human-Centric Computing, 165-172, 2004 (pdf), Best Paper Award
Visually Customizing Inference Rules About Apples and Oranges, Margaret M. Burnett and Martin Erwig, 2nd IEEE Int. Symp. on Human Centric Computing Languages and Environments, 140-148, 2002 (pdf)
Adding Apples and Oranges, Martin Erwig and Margaret M. Burnett, 4th Int. Symp. on Practical Aspects of Declarative Languages, LNCS 2257, 173-191, 2002 (pdf)
Spreadsheets are likely to be full of errors and this can cause organizations to lose millions of dollars. However, finding and correcting spreadsheet errors is extremly hard and consumes a lot of time.
Probably inspired in database systems (personal guess) and how database management systems (DBMS) mantain the database consistent after every update and transaction, Martin Erwig, Robin Abraham, Irene Cooperstein and Steve Kollmansberger designed and implemented Gencel. Gencel is an extension to Excel, based on the concept of a spreadsheet template, which captures the essential structure of a spreadsheet and all of its future evolutions. Such a template ensures that every update is safe, avoiding reference, range and type errors.
Templates can be created with the editor ViTSL, similar to Excel (with additional features to design templates).
Selected Publications
Gencel: A Program Generator for Correct Spreadsheets, Martin Erwig and Robin Abraham and Irene Cooperstein and Steve Kollmansberger, Journal of Functional Programming, 2005, to appear (pdf)
Visual Specifications of Correct Spreadsheets, Robin Abraham, Martin Erwig, Steve Kollmansberger, and Ethan Seifert, IEEE Int. Symp. on Visual Languages and Human-Centric Computing, 2005, to appear (pdf)
Automatic Generation and Maintenance of Correct Spreadsheets, Martin Erwig, Robin Abraham, Irene Cooperstein, and Steve Kollmansberger, 27th IEEE Int. Conf. on Software Engineering, 136-145, 2005 (pdf)
Goal-Directed Debugging of Spreadsheets, Robin Abraham and Martin Erwig, VLHCC '05: Proceedings of the 2005 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC'05), 2005 (pdf)
Simon Peyton Jones, together with Margaret Burnett and Alan Blackwell, describe extensions to Excel that allow to integrate in the spreadsheet grid user-defined functions. That take us from a end-user programming paradigm to an extended system, which provides some of the capabilities of a general programming language.
Selected Publications
A user-centred approach to functions in Excel. Simon Peyton Jones, Margaret Burnett, Alan Blackwell. Proc International Conference on Functional Programming, Uppsala, Sept 2003 (ICFP'03), pp 165-176, 12 pages. (pdf)
Champagne Prototyping: A Research Technique for Early Evaluation of Complex End-User Programming Systems. Alan Blackwell, Margaret Burnett, Simon Peyton Jones. 12 pages, March 2004. (pdf)
José Nuno Oliveira describes a pointfree calculus and refinement laws for spreadsheet normalization.
He shows how a binary representation of an n-ary relation makes sense in database theory context, and how lengthy formulae can become very simple and elegant. As an example, it follows the definition of functional dependency satisfiability in the two calculus:
Pointwise calculus (classical)
Pointfree calculus
Selected Publications
Functional dependency theory made 'simpler', J.N. Oliveira, Technical report, DI-Research.PURe-05.01.01, January 2005. (pdf)
Our project
Research plan
The project proposal for which a BIC grant has been awarded is available:
In this proposal the following deliverables are expected:
A Spreadsheet Transformation and Analysis API -- Develop a Haskell library that supports the processing of spreadsheets. The functionality offered by this library should include: (1) conversion of spreadsheets to and from XML, including structured representation of formulas. (2) marshaling between the XML repre- sentation of spreadsheets and the strongly-typed Haskell representation. (3) functions for querying and transforming the various elements of the Haskell representation. The Spreadsheet API should become part of the UMinho Haskell Library initiative.
A Spreadsheet Type Reconstruction Component -- Based on the above API, implement an algorithm for reconstruction of types in a spreadsheet. The algorithm analysis the use of cells in formulas, and computes type and sub-type relations between cells. This component will be useful for testing purposes and error detection in spreadsheets.
A Relational Data Model Extraction Component -- Based on the Spreadsheet API, implement an algorithm for extraction of the underlying data model of a spreadsheet. In particular, the algorithm detects which cells are used as identifying keys. Based on this, a relational data model will be inferred, including primary keys, foreign key relationships and integrity constrains. This component will be useful to support migration from spreadsheets solutions to databases solutions in industrial contexts.
Spreadsheet Quality Assessment Case Study -- The developed components for type reconstruction and data model extraction will be applied to a set of commercially used spreadsheets with the ob jective of quality assessment. In particular, they will be used to detect errors, and uncover the underlying data model of the involved spreadsheets. The results and the methodology of the quality assessment will be described in a spreadsheet quality assessment report.
Possible integration with other projects
To promote the adoption of the Gencel system, tools that extract specifications from arbitrary spreadsheets are needed.
Deliverable 3, based on José Nuno Oliveira's research, could be a nice tool to integrate with Gencel.
For read only access you can use the username anonymous (password anonymous).
For read-write access, you should be a member of the PUReCvsGroup? (contact an
administrator for that) and use the twiki name and password.
Check out the repository
With:
cvs -d :pserver:username@haskell.di.uminho.pt:/mnt/ds/cvsroot checkout PURe
This gives you a directory Research.PURe with subdirectories such as software and papers. This is your local copy of the repository.
Update your local copy
Change to any directory within your local copy of the repository, and update it with:
cvs upd -dP
The -dP options tell CVS to also synchronize subdirectories, if they are non-empty.
Add files
If you create new files or directories in your local copy, and you can register them for addition with:
cvs add filename
This does not yet store the file in the repository. You still need to commit it (see below).
Commit local modifications into the repository
After making modifications in you local copy (changing or adding files) you can commit them to the repository as follows:
cvs commit
Note
For all this to work, you need an environment variable CVS_RSH set to ssh such that cvs will make a connection with the server on which the repository resides via ssh.
VooDooM: A transformation tool for VDM-SL.
FUNCTIONALITYVooDooM reads VDM-SL specifications and applies transformation rules to
the datatypes that are defined in them to obtain a relational
representation for these datatypes. The relational representation can be
exported as:
VDM-SL datatypes (inserted back into the original specification)
SQL table definitions (can be fed to a relational DBMS)
USAGE
Just type VooDooM at the command line, and follow instructions.
IMPLEMENTATIONVooDooM makes use of the parsing, pretty-printing, and traversal support for VDM-SL provided by VooDooMFront. This means that VooDooM uses a VDM-SL grammar specified in SDF together with Haskell modules generated from this grammar using the Sdf2Haskell? tool of the Strafunski bundle.
DOCUMENTATION
The relational calculus implemented by VooDooM is described in the following paper:
In addition to the calculus itself, the paper descibes the use of strategic programming in its implementation, using the Haskell-based Strafunski bundle.
The grammar is based on the ISO/IEC 13817-1:1996 reference document that describes the concrete and abstract syntax of VDM-SL.
Documentation
Technical Report: Development of an Industrial Strength Grammar for VDM
The development of the VDM grammar in SDF is documented in the following technical report:
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. (pdf)
The report describes the grammar engineering methodology that was applied, the tools employed, and the various stages of evolution during grammar development. In particular, the report shows metrics data collected using SdfMetz for all 48 development versions of the grammar. A pretty-printed version of the grammar is included as appendix.
Browsable grammar
A browsable HTML rendering of the VDM-SL grammar in SDF is available from:
By clicking on non-terminal names one can easily navigate and explore the grammar structure.
Extreme Grammaring Presentation
Although parsing is a subset of a well studied area like compilers, grammars were always looked upon as "the ugly duckling".
In this presentation I propose a novel methodology, baptized "Extreme Grammaring", for developing grammars using the SDF (Syntax Definition Formalism), inspired in Extreme Programming.
This methodology made possible the development of an industrial strength grammar for ISO VDM-SL, one of the most common languages used for formal specification.
"Extreme Grammaring" presentation slides (Presented on December, 21 in the PUReCafe)
Haskell front-end with parsing, AST outputting and pretty-printing support.
For detailed description of each release, see the remarks below as well as the README and ChangeLog files included in each distribution.
See VDMGrammarEvolution for metric values for all versions.
Upcoming releases
Version 2.0: This version will contain the front-end for Java, supporting parsing, tree building, and tree traversal, most probably following the JJForester approach.
Related
VooDooM is a tool that converts VDM-SL data types to relational form, and exports them as SQL.
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ...
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ...
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ...
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ...
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ...
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ...
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ...
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ...
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ...
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ...
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ...
Sep 18 Paper Towards a Coordination Model for Interactive Systems by MarcoAntonioBarbosa, JoseCampos and LuisSoaresBarbosa has been accepted for FMIS'06 (Macau ...
TWiki.Research/PURe Web Preferences The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site level preferences ...
Spreadsheet Understanding The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering ...
One of the research topics of the Research.PURe Project is development of generic program slicing techniques. Contributors Personal.Nuno Rodrigues Patrick ...
UMinho Haskell Software Libraries Tools The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that ...
Using CVS For the current state of affairs you can take a peek at our repository. To use CVS do the following: Login to the repository With: cvs d :pserver:username ...
News May 18, 2005 A browsable version of the VDM SL grammar is now online. April 29, 2005 A report came out on the development of the VDM grammar in SDF. February ...
Haskell Activities and Communities Report Entries submitted by the LMF group at the Informatics Department of the University of Minho. Libraries 1. Pointless Haskell ...
This is a subscription service to be automatically notified by e mail when topics change in this Research/PURe web. This is a convenient service, so you do not have ...
VooDooM : A transformation tool for VDM SL. FUNCTIONALITY VooDooM reads VDM SL specifications and applies transformation rules to the datatypes that are defined ...
body { background color : lightgray; font family: Verdana, Arial, Helvetica, sans serif; font size: 12px ; } a:link { text decoration : none ; color : darkblue ...
What is ChopaChops? ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection: JReach ...
This page lists links to papers mentioned in the FCT proposal entitled "Software Analysis Lab": 1. http://www.di.uminho.pt/~joost.visser/publications/AToolBasedMethodologyForSoftwarePortfolioMonitoring ...
Program Understanding and Re-engineering: Calculi and Applications
The aim of the PURe research project is to develop calculi for program understanding and re-engineering. Formal techniques that have traditionally been developed for and applied to forward engineering of software, are applied in reverse direction, i.e. for the understanding and re-engineering of existing (legacy) program code. Read more.
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ...
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ...
What is ChopaChops? ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection: JReach ...
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ...
body { background color : lightgray; font family: Verdana, Arial, Helvetica, sans serif; font size: 12px ; } a:link { text decoration : none ; color : darkblue ...
One of the research topics of the Research.PURe Project is development of generic program slicing techniques. Contributors Personal.Nuno Rodrigues Patrick ...
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ...
Haskell Activities and Communities Report Entries submitted by the LMF group at the Informatics Department of the University of Minho. Libraries 1. Pointless Haskell ...
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ...
Sep 18 Paper Towards a Coordination Model for Interactive Systems by MarcoAntonioBarbosa, JoseCampos and LuisSoaresBarbosa has been accepted for FMIS'06 (Macau ...
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ...
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ...
UMinho Haskell Software Libraries Tools The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that ...
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ...
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ...
This page lists links to papers mentioned in the FCT proposal entitled "Software Analysis Lab": 1. http://www.di.uminho.pt/~joost.visser/publications/AToolBasedMethodologyForSoftwarePortfolioMonitoring ...
Spreadsheet Understanding The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering ...
Using CVS For the current state of affairs you can take a peek at our repository. To use CVS do the following: Login to the repository With: cvs d :pserver:username ...
VooDooM : A transformation tool for VDM SL. FUNCTIONALITY VooDooM reads VDM SL specifications and applies transformation rules to the datatypes that are defined ...
News May 18, 2005 A browsable version of the VDM SL grammar is now online. April 29, 2005 A report came out on the development of the VDM grammar in SDF. February ...
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ...
This is a subscription service to be automatically notified by e mail when topics change in this Research/PURe web. This is a convenient service, so you do not have ...
TWiki.Research/PURe Web Preferences The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site level preferences ...
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ...
This is a subscription service to be automatically notified by e-mail when topics change in this Research/PURe web. This is a convenient service, so you do not have to come back and check all the time if something has changed. To subscribe, please add a bullet with your WikiName in alphabetical order to this list:
Format: <space><space><space>, followed by: * Main.yourWikiName (if you want that the e-mail address in your home page is used) * Main.yourWikiName - yourEmailAddress (if you want to specify a different e-mail address) * Main.anyTWikiGroup (if you want to notify all members of a particular TWikiGroup)
Related topics:TWikiUsers, TWikiRegistration
The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site-level preferences in TWikiPreferences, and can be overwritten by user preferences (your personal topic, i.e. TWikiGuest in the TWiki.Main web)
Preferences:
If yes, set SITEMAPLIST to on, do not set NOSEARCHALL, and add the "what" and "use to..." description for the site map. Make sure to list only links that include the name of the web, e.g. Research/PURe.Topic links.
Set SITEMAPLIST = on
Set SITEMAPWHAT = PURe
Set SITEMAPUSETO = Program Understanding and Re-engineering: Calculi and Applications
Exclude web from a web="all" search: (Set to on for hidden webs)
Set NOSEARCHALL =
Default template for new topics and form(s) for this web:
WebTopicEditTemplate? : Default template for new topics in this web. (Site-level is used if topic does not exist)
Web preferences that are not allowed to be overridden by user preferences:
Set FINALPREFERENCES = WEBTOPICLIST, DENYWEBVIEW, ALLOWWEBVIEW, DENYWEBCHANGE, ALLOWWEBCHANGE, DENYWEBRENAME, ALLOWWEBRENAME
Notes:
A preference is defined as: 6 spaces * Set NAME = value Example:
Set WEBBGCOLOR = #FFFFC0
Preferences are used as TWikiVariables by enclosing the name in percent signs. Example:
When you write variable %WEBBGCOLOR% , it gets expanded to #CCCCCC .
The sequential order of the preference settings is significant. Define preferences that use other preferences first, i.e. set WEBCOPYRIGHT before WIKIWEBMASTER since %WEBCOPYRIGHT% uses the %WIKIWEBMASTER% variable.
You can introduce new preferences variables and use them in your topics and templates. There is no need to change the TWiki engine (Perl scripts).
TWiki's Research/PURe web
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe
The Research/PURe web of TWiki. TWiki is a Web-Based Collaboration Platform for the Corporate World.en-usCopyright 2020 by contributing authorsTWiki Administrator [webmaster@di.uminho.pt]The contributing authors of TWikiTWikiDIUM.Research/PURe
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe
/twiki/pub/Main/LocalLogos/um_eengP.jpgProjectSummary
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/ProjectSummary
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ... (last changed by LuisSoaresBarbosa)2009-03-02T19:23:42ZLuisSoaresBarbosaWebHome
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebHome
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ... (last changed by LuisSoaresBarbosa)2009-03-02T19:18:53ZLuisSoaresBarbosa2LT
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/2LT
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ... (last changed by TiagoAlves)2007-12-05T23:40:49ZTiagoAlvesWebSideBar
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebSideBar
Navigation Home PURe Café Publications Software Related Group Conferences IKF Project News (last changed by JoseBacelarAlmeida)2007-11-04T19:25:44ZJoseBacelarAlmeidaFlexibleSkinLeftBar
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/FlexibleSkinLeftBar
Project Home PURe Café Publications Software Related Group Conferences Books IKF Project Navigation Users Changes Index Statistics Webs Search (last changed by JoseBacelarAlmeida)2007-11-04T19:21:09ZJoseBacelarAlmeidaSdfMetz
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/SdfMetz
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaPURePublications
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PURePublications
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaPUReNewsArchive
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReNewsArchive
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaHaGLR
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/HaGLR
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaCamila
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/Camila
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ... (last changed by JoseBacelarAlmeida)2007-11-04T18:58:50ZJoseBacelarAlmeidaCoddFish
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/CoddFish
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ... (last changed by JoostVisser)2007-07-11T21:47:50ZJoostVisserXsdMetz
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/XsdMetz
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ... (last changed by JoostVisser)2007-07-11T21:47:15ZJoostVisserPUReCafe
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReCafe
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ... (last changed by JoseBacelarAlmeida)2007-06-28T11:45:16ZJoseBacelarAlmeidaPUReCafeTalk1
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReCafeTalk1
Invitation to Wiki Basic Principles WikiName TextFormattingRules Edit via browser Distributed ownership Successful Wikis ... (last changed by JoseBacelarAlmeida)2007-06-28T11:42:14ZJoseBacelarAlmeidaWebTopicActions
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebTopicActions
(last changed by JoseBacelarAlmeida)2007-05-29T16:23:54ZJoseBacelarAlmeidaWebSearchAdvanced
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebSearchAdvanced
(last changed by TWikiGuest)2007-05-17T14:51:23Zguest
NOTE: the 2LT project is moving to: 2LT at Google Code.
A two-level data transformation consists of a type-level transformation of a data format coupled with value-level transformations of data instances corresponding to that format. Examples of two-level data transformations include XML schema evolution coupled with document migration, and data mappings that couple a data format mapping with conversions between mapped formats.
In the 2LT project we apply theories of calculational data refinement and of point-free program transformation to two-level transformations.
DATA REFINEMENT
A refinement of an abstract type A into a concrete type B, is witnessed by conversion functions to:A->B (injective and total) and from:B->A (surjective and partial).
TYPE-CHANGING REWRITES
Such data refinements can be modeled by a type-changing rewrite system, where each rewite step takes the form A => (B,to,from). In other words, each step produces not only a new type, but also the conversion functions between the old and new type. By repeatedly applying such rewrite steps, complex conversion functions are calculated incrementally while a new type is being derived.
PROGRAM CALCULATION
The complex conversion functions derived after type-changing rewriting can be subjected to subsequent simplification using laws of point-free program calculation. The same holds for compositions of conversion functions with queries on the target or source data types. Such simplifications then amount for instance to:
generation of efficient low-level data migrations from high-level migrations
program migration of queries on the source data type to queries on a target data type
Apart from transformation of point-free functions, we have implemented rewrite systems for transformation of structure-shy functions (XPath expressions and strategic functions), and for transformation of binary relation expressions.
HASKELL IMPLEMENTATION
We have implemented both type-changing rewrite systems and type-preserving rewrite systems in Haskell. The implementations involve generalized algebraic datatypes (GADTs), strategy combinators, type-safe representations of types and of functions, and other advanced Haskell techniques.
Alcino Cunha, Joost Visser. Strongly Typed Rewriting For Coupled Software Transformation. In Proceedings of RULE 2006, ENTCS, to appear. (PDF).
Pablo Berdaguer, Alcino Cunha, Hugo Pacheco, Joost Visser. Coupled Schema Transformation and Data Conversion For XML and SQL. In PADL 2007: Practical Aspects of Declarative Languages, to appear. (PDF).
Alcino Cunha and Joost Visser, Transformation of Structure-Shy Programs, Applied to XPath Queries and Strategic Functions, In Proceedings of the 2007 ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation, PEPM 2007, to appear. (PDF)
Claudia Mónica Necco, José Nuno Oliveira, and Joost Visser, Extended Static Checking By Strategic Rewriting of Pointfree Relational Expressions, Draft of februari 3, 2007. (PDF)
TECHNICAL REPORT
Alcino Cunha, José Nuno Oliveira, Joost Visser. Type-safe Two-level Data Transformations -- with derecursivation and dynamic typing, DI-Research.PURe-06.03.01, March 2006. (PDF).
The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined. On the one hand, it includes experiments of expressing VDM's data types (e.g. maps, sets, sequences), data type invariants, pre- and post-conditions, and such within the Haskell language. On the other hand, it includes the translation of VDM specifications into Haskell programs.
This is a continuation (or revival) of the original Camila system, see http://camila.di.uminho.pt.
The Camila revival project is being developed in distinct phases, which are briefly described below.
Phase I (Camila Revival)
Deliverables:
Prototype camila interpreter in Haskell
Camila Prelude modules in Haskell
Both deliverables are integrated into the UMinho Haskell Software distribution.
Documents
"PURe CAMILA: A system for software development using formal methods" - Alexandra Mendes and João Ferreira, LabMF 2005 - (Report) (Slides)
Examples
In directory Camila/Examples you will find some examples (if you intend to add examples, you sould put them in this directory too). Before loading them in the interpreter,
you will need to compile it. For example, to use the example Folder:
From libraries directory, run ghc --make Camila/Examples/Folder.hs -package plugins
From tools/Camila directory and after compiling the interpreter:
make run
:l Camila.Examples.Folder
create f := new Folder
eval f opread
(If you want to see more examples, please see Report -- Chapter 5 )
Phase II (VDM++ features)
VDM++, in comparison with VDM has the following extra features:
Allows the definition of classes and objects
Inheritance (specialization and generalization)
Operations and functions to describe functional behaviour of the objects
This report explains how to mimic VDM++ features (parallelism not included) in Haskell.
Phase III (Camila enriched with components)
(to appear)
Downloads
You can find the latest version of CAMILA in Research.PURe CVS (see PUReSoftware). You will need hs-plugins package.
To use the prototype interpreter, you have to compile it (just run make in directory tools/Camila) -- don't forget you need to install hs-plugins package before doing this.
To run it just do make run.
Note: At the moment, you will have to compile all the examples you want to run.
(All these steps will be simplified in the future, so stay tuned)
A stand-alone release is also available:
ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection:
JReach: derives package graphs from Java sources, and allows them to be sliced or chopped according to various criteria.
JReach
A package graph contains nodes that represent Java packages and types (interfaces or classses) and their interrelationships. A package graph contains edges to represent the following types of relationships:
nesting: a type is nested inside a package or inside another type.
import: a type imports other types.
inherit: a type inherits from another type (class from class, or interface from interface).
Using JReach, one can compute slices and chops of the above package graph. For instance, the forward slice from software_improvers.clonedetection.metric.CloneDetector:
Or the backward slice from java.util.List and java.util.ArrayList:
And finally, the chop between software_improvers.clonedetection.metric.CloneDetector on one hand, and java.util.List and java.util.ArrayList on the other hand:
Additionally, JReach also allows to compute the union between slices rather than the intersection.
Graph slicing and chopping
The ChopaChops tools use functionality from the UMinho Haskell Libraries for representing and manipulating graphs. In particular, they use the modules in the Relation package.
CoddFish makes extensive use of heterogenous collections and type-level programming.
HETEROGENEOUS COLLECTIONS
A relational database is modeled as a heterogeneous collection of tables. A table, in turn, is modeled as a heterogeneous collection of attributes (the header of the table) and a Map of key values to non-key values (the rows of the table). Both the key and non-key values are stored again in a heterogeneous collection. In addition, heterogeneous collections are used to model the arguments and results of database operations, and to model functional dependencies.
TYPE-LEVEL PROGRAMMING
Type-level programming is used to maintain the consistency between header and rows, and between functional dependencies and tables. Type-level predicates are provided to check whether tables and functional dependencies are in particular normal-forms, or not.
RESEARCH PAPER
The essentials of CoddFish are described in the following paper:
Alexandra Silva and Joost Visser, Strong Types for Relational Databases (Functional Pearl). In Proceedings of Haskell Workshop 2006, to appear. pdf
API
Generated documentation of the API of CoddFish will appear here.
Downloads.
CoddFish is a sub-library of the UMinho Haskell Libraries. A stand-alone release is also available:
HaGLR provides support for Generalized LR parsing in Haskell.
Documentation
João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing in Haskell. Paper presented at the 5th summer school on Advanded Functional Programming.
Haddock documentation: see PUReSoftware, in particular the modules under Language.ContextFree.
João Fernandes. Generalized LR Parsing in Haskell. Technical report DI-Research.PURe-04.11.01. pdf
Haskell Activities and Communities Report
Entries submitted by the LMF group at the Informatics Department of the University of Minho.
[Libraries]
1. Pointless Haskell
Pointless Haskell is a library for point-free programming with recursion patterns defined as hylomorphisms. It is part of the UMinho Haskell libraries that are being developed at the University of Minho. The core of the library is described in "Point-free Programming with Hylomorphisms" by Alcino Cunha.
Pointless Haskell also allows the visualization of the intermediate data structure of the hylomorphisms with GHood. This feature together with the DrHylo? tool allows us to easily visualize recursion trees of Haskell functions, as described in "Automatic Visualization of Recursion Trees: a Case Study on Generic Programming" (Alcino Cunha, In volume 86.3 of ENTCS: Selected papers of the 12th International Workshop on Functional and (Constraint) Logic Programming. 2003).
The Pointless Haskell library is available from http://wiki.di.uminho.pt/bin/view/Alcino/PointlessHaskell.
[Tools]
1. DrHylo?DrHylo? is a tool for deriving hylomorphisms from Haskell program code. Currently, DrHylo? accepts a somewhat restricted Haskell syntax. It is based on the algorithm first presented in the paper Deriving Structural Hylomorphisms From Recursive Definitions at ICFP'96 by Hu, Iwasaki, and Takeichi. To run the programs produced by DrHylo? , you need the Pointless library.
DrHylo? is available from http://wiki.di.uminho.pt/bin/view/Alcino/DrHylo.
2. VooDooMVooDooM reads VDM-SL specifications and applies transformation rules to the datatypes that are defined in them to obtain a relational representation for these datatypes. The relational representation can be exported as VDM-SL datatypes (inserted back into the original specification) and/or SQL table definitions (can be fed to a relational DBMS). The first VooDooM prototype was developed in a student project by Tiago Alves and Paulo Silva. Currently, the development of VooDooM is continued in the context of the IKF-P project (Information Knowledge Fusion, http://ikf.sidereus.pt/) and will include the generation of XML and Haskell
VooDooM is available from http://wiki.di.uminho.pt/bin/view/Research.PURe/VooDooM.
3. HaLex?HaLeX? is a Haskell library to model, manipulate and animate regular languages. This library introduces a number of Haskell datatypes and the respective functions that manipulate them, providing a clear, efficient and concise way to define, to understand and to manipulate regular languages in Haskell. For example, it allows the graphical representation of finite automata and its animation, and the definition of reactive finite automata. This library is described in the paper presented at FDPE'02.
4. HaGLRHaGLR is an implementation of Generalized LR parsing in Haskell. Apart from parsing with the GLR algorithm, it supports parsing with the LR algorithm, visualization of deterministic and non-deterministic finite automata, and export of ASTs in XML or ATerm format. As input, HaGLR accepts either plain context-free grammars, or SDF syntax definitions. The SDF front-end is implemented as an extension of the Sdf2Haskell? generator. HaGLR's functionality can also be accessed as library functions, available under the ContextFree? subdivision of the UMinho Haskell Libraries. HaGLR was implemented by João Fernandes and João Saraiva.
HaGLR is available from http://wiki.di.uminho.pt/twiki/bin/view/Research.PURe/HaGLR.
5. LRC
Lrc is a system for generating efficient incremental attribute evaluators. Lrc can be used to generate language based editors and other advanced interactive environments. Lrc can generate purely functional evaluators, for instance in Haskell. The functional evaluators can be deforested, sliced, strict, lazy. Additionally, for easy reading, a colored LaTeX? rendering of the generated functional attribute evaluator can be generated.
6. Sdf2Haskell?Sdf2Haskell? is a generator that takes an SDF grammar as input and produces support for GLR parsing and customizable pretty-printing. The SDF grammar specifies concrete syntax in a purely declarative fashion. From this grammar, Sdf2Haskell? generates a set of Haskell datatypes that define the corresponding abstract syntax. The Scannerless Generalized LR parser (SGLR) and associated tools can be used to produce abstract syntax trees which can be marshalled into corresponding Haskell values.
Recently, the functionality of Sdf2Haskell? has been extended with generation of pretty-print support. From the SDF grammar, a set of Haskell functions is generated that defines an pretty-printer that turns abstract syntax trees back into concrete expressions. The pretty-printer is updatable in the sense that its behaviour can be modified per-type by supplying appropriate functions.
Sdf2Haskell? is distributed as part of the Strafunski bundle for generic programming and language processing (http://www.cs.vu.nl/Strafunski). Sdf2Haskell? is being maintained by Joost Visser (Universidade do Minho, Portugal).
[Research Groups]
The Logic and Formal Methods group at the Informatics Department of the University of Minho, Braga, Portugal. http://www.di.uminho.pt/~glmf.
We are a group of about 12 staff members and various PhD? and MSc students. We have shared interest in formal methods and their application in areas such as data and code reverse and re-engineering, program understanding, and communication protocols. Haskell is our common language for teaching and research.
Haskell is used as first language in our graduate computers science education (section [Haskell in Education]). José Valença and José Barros are the authors of the first (and only) Portuguese book about Haskell, entitled "Fundamentos da Computação" (ISBN 972-674-318-4). Alcino Cunha has developed the Pointless library for pointfree programming in Haskell (section [Tools and libraries]), as well as the DrHylo? tool that transforms functions using explicit recursion into hylomorphisms. Supervised by José Nuno Oliveira, students Tiago Alves and Paulo Silva are developing the VooDooM tool, which transforms VDM datatype specifications into SQL datamodels and students João Ferreira and José Proença will soon start developing CPrelude.hs, a formal specification modelling tool generating Haskell from VDM-SL and CAMILA. João Saraiva is responsible for the implementation of the attribute system LRC, which generates (circular) Haskell programs. He is also the author of the HaLex? library and tool, which supports lexical analysis with Haskell. Joost Visser has developed Sdf2Haskell? , which generates GLR parsing and customizable pretty-printing support from SDF grammars, and which is distributed as part of the Strafunski bundle. Most tools and library modules develop by the group are organized in a single infrastructure, to facilitate reuse, which can be obtained as a single distribution under the name UMinho Haskell Libraries and Tools.
The group has recently started the 3-year project called Research.PURe which aims to apply formal methods to Program Understanding and Reverse Engineering. Haskell is used as implementation language, and various subprojects have been initiated, including Generic Program Slicing.
[Haskell in Education]
Haskell is heavily used in the undergraduate curricula at Minho. Both Computer Science and Systems Engineering students are taught two Programming courses with Haskell. Both programmes of studies fit the "functional-first" approach; the first course is thus a classic introduction to programming with Haskell, covering material up to inductive datatypes and basic monadic input/output. It is taught to 200 freshers every year. The second course, taught in the second year (when students have already been exposed to other programming paradigms), focusses on pointfree combinators, inductive recursion patterns, functors and monads; rudiments of program calculation are also covered. A Haskell-based course on grammars and parsing is taught in the third year, where the HaLeX? library is used to support the classes.
Additionally, in the Computer Science curriculum Haskell is used in a number of other courses covering Logic, Language Theory, and Semantics, both for illustrating concepts, and for programming assignments. Minho's 4th year course on Formal Methods (a 20 year-old course in the VDM tradition) is currently being restructured to integrate a system modelling tool based on Haskell and VooDooM. Finally, in the last academic year we ran an optional, project-oriented course on Advanced Functional Programming. Material covered here focusses mostly on existing libraries and tools for Haskell, such as YAMPA - functional reactive programming with arrows, the WASH library, the MAG system, the Strafunski library, etc. This course benefitted from visits by a number of well-known researchers in the field, including Ralf Laemmel and Peter Thiemann.
Combining Formal Methods and Functional Strategies Regarding the Reverse Engineering of Interactive Applications
João Carlos Silva
Graphical user interfaces (GUIs) make software easy to use by providing the user with visual controls. Therefore, correctness of GUI's code is essential to the correct execution of the overall software. Models can help in the evaluation of interactive applications by allowing designers to concentrate on its more important aspects. This paper describes our approach to reverse engineer an abstract model of a user interface directly from the GUI's legacy code. We also present results from a case study. These results are encouraging and give evidence that the goal of reverse engineering user interfaces can be met with more work on this technique.
The Quality Economics of Defect-Detection Techniques
Stefan Wagner, Software & Systems Engineering, Technische Universitaet Muenchen, Institut fuer Informatik
Analytical software quality assurance (SQA) constitutes a significant part of the total development costs of a typical software system. Typical estimates say that up to 50\% of the costs can be attributed to defect detection and removal. Hence, this is a promising area for cost-optimisations. The main question in that context is then how to use those different techniques in a cost-optimal way. In detail this boils down to the questions to use (1) which techniques, (2) in which order, and (3) with what effort. This talk describes an analytical and stochastic model of the economics of analytical SQA that can be used to analyse and answer these questions. The practical application is shown on the example of a case study on model-based testing in the automotive domain.
The end of the Research.PURe project is approaching. We will be able to look back at a successful project with lots of interesting deliverables. But now it becomes urgent to reflect on what comes after Research.PURe. A deadline for new FCT proposals is July 31. We will initiate discussion about concrete ideas for such a follow-up project.
(1) Prototype Implementation of an Algebra of Components in Haskell
Jácome Cunha
The starting point to this project are state-based systems modeled as components, i.e, "black boxes" that have "buttons" or "ports" to communicate with the whole system. A list of operators to connect these components is given. A possible way to implement components as coalgebras in Haskell is shown. Finally, a tool to generate a component from a state-based system definition is implemented.
This communication is a follow up of [1]. We show how to model some of the key concepts of VDM++ in Haskell. Classes, objects, operations and inheritance are encoded based on the recently developed OOHaskell library.
[1] Camila Revival: VDM meets Haskell, Joost Visser, J.N. Oliveira, L.S. Barbosa, J.F. Ferreira, and A. Mendes. Overture Workshop, colocated with Formal Methods 2005.
This communication is an attempt to apply the calculational style underlying the so-called Bird-Meertens formalism to generalised coinduction, as defined in F. Bartels' thesis. In particular, equational properties of such generic recursion scheme are given, relying on its universal characterisation. We also show how corresponding calculational kits for particular instances of the general coinduction are derived by specialisation.
We present a local graph-rewriting system capable of deciding equality on a fragment of the language of point-free expressions. The fragment under consideration is quite limited since it does not includes exponentials. Nevertheless, it constitutes a non-trivial exercise due to interactions between additive and multiplicative laws.
We propose a novel, comonadic approach to dataflow (stream-based) computation. This is based on the observation that both general and causal stream functions can be characterized as coKleisli arrows of comonads and on the intuition that comonads in general must be a good means to structure context-dependent computation. In particular, we develop a generic comonadic interpreter of languages for context-dependent computation and instantiate it for stream-based computation. We also discuss distributive laws of a comonad over a monad as a means to structure combinations of effectful and context-dependent computation. We apply the latter to analyse clocked dataflow (partial streams based) computation.
Joint work with Varmo Vene, University of Tartu. Appeared in Proc of APLAS 2005.
We define a strongly-typed model of relational databases and operations on them. In this model, table meta-data is represented by type-level entities that guard the semantic correctness of all database operations at compile time. The model relies on type-class bounded and parametric polymorphism and we demonstrate its encoding in the functional programming language Haskell. Apart from the standard relational database operations, such as selection and joins, we formalize functional dependencies and normalization. We show how functional dependency information can be represented at the type level, and can be transported through operations from argument types to result types. The model can be used for static query checking, but also as the basis for a formal, calculational approach to database design, programming, and migration. The model is available as sub-library of the UMinho Haskell Libraries, and goes under the name of CoddFish.
Functional programming provides different programming styles for programmers to write their programs in. The differences are even more explicit under a lazy evaluation model, under which a computation of a value is only triggered upon its need. When facing the challenge of implementing solutions for multiple traversals algorithm problems, the functional programmer often tends to assume himself as the decision maker of all the implementation details: how many traversals to define, in which order to schedule them, which intermediate structures to define and traverse, just to name some. Another sub-paradigm is available, though. Given the proper will and sufficient practice, multiple traversal algorithms are possible to be implemented as lazy circular programs, where some of the programming work is handed to the lazy machinery.In this talk I will present a calculational rule to convert multiple traversal programs into single-pass circular ones. Feedback is more than expected, it is wanted!
A BIC was recently assigned to Zé Pedro Correia. Its subject is to develop a tool to manipulate point-free expressions, according to transformation laws, in order to construct a point-free proof. This talk will serve to introduce this project to the Research.PURe group, presenting the work done so far and the work to do. We also expect to collect some opinions on the general expected "behaviour" of the tool.
We constructed a tool, called VooDooM, which converts datatypes in VDM-SL into SQL relational data models. The conversion involves transformation of algebraic types to maps and products, and pointer introduction. The conversion is specified as a theory of refinement by calculation. The implementation technology is strategic term rewriting in Haskell, as supported by the Strafunski bundle. Due to these choices of theory and technology, the road from theory to practise is straightforward.
Na programação funcional existem vários estilos de programação, não havendo consenso quanto a qual será o melhor. Dois estilos opostos são, por exemplo, pointfree e pointwise, que se distinguem principalmente por no primeiro serem utilizadas variáveis e no segundo não. No trabalho foi introduzida uma possível descrição de expressões em pointfree e em pointwise, de tal forma que estas fossem o mais simples possível. Depois foi introduzido um processo que permite converter expressões entre estes dois tipos. Foram também consideradas outras linguagens pointwise que podem ser convertidas para o tipo pointwise originalmente criado. O principal objectivo foi tornar possível a transição de código pointwise para pointfree, utilizando bases teóricas e com a garantia de que não sejam introduzidos erros no processo de conversão.
PURe CAMILA: A System for Software Development using Formal Methods
João F. Ferreira
This work consists in the first steps for the re-implementation of CAMILA, which is a software development environment intended to promote the use of formal methods in industrial software environments. The new CAMILA, also called Research.PURe CAMILA, is written in Haskell and makes use of monadic programming. A small prototype interpreter was created, but the purpose of this work is to study the concepts behind such a tool, such as datatype invariants and partial functions.
In this paper, we present a collection of aspect-oriented refactorings covering both the extraction of aspects from object-oriented legacy code and the subsequent tidying up of the resulting aspects. In some cases, this tidying up entails the replacement of the original implementation with a different, centralized design, made possible by modularization. The collection of refactorings includes the extraction of common code in various aspects into abstract superaspects. We review the traditional object-oriented code smells in the light of aspect-orientation and propose some new smells for the detection of crosscutting concerns. In addition, we propose a new code smell that is specific to aspects.
Miguel Vilaça will introduce the topic of designing a visual language for pointfree programming. After this, we will exchange ideas about how to approach this problem.
In the context of Joost Visser's Spreadsheets under Scrutiny talk, I have been looking at refinement laws for spreadsheet normalization. Back to good-old `functional dependency theory', D. Maier's book etc, I ended up by rephrasing of the standard theory using the binary relation pointfree calculus. It turns out that the theory becomes simpler and more general, thanks to the calculus of 'simplicity' and coreflexivity. This research also shows the effectiveness of the binary relation calculus in «explaining» and reasoning about the n-ary relation calculus «à la Codd».
Grammars are to parser generators what programming languages are to compilers. Although parsing is a subset of a well studied area like compilers, grammars were always looked upon as "the ugly duckling". In this presentation I will propose a methodology for developing grammars using the SDF (Syntax Definition Formalism) inspired in Extreme Programming. This methodology was used to develop a grammar for ISO VDM-SL, one of the most common languages used for formal specification. The grammar is available from: VooDooMFront.
Damijan Rebernak from Maribor University, Slovenia, will present a talk on grammar-based tools. NOTE: The talk will start at 12:00, instead of the usual hour of 11:00.
In the Pure Workhsop last Sptember a limitation of the Hylo-shift law for program calculation was identified, and a possible way of solving it was then discussed. In this talk I will present my current understanding of how a generalized version of the law can be formalized.
In this talk we will show how Haskell can be used to process spreadsheets. We will demonstrate a prototype that takes an excell workbook as input, converts it to gnumeric's xml representation of spreadsheets with formulas, reads and parses the xml representation into a strongly type set of haskell datatypes, and finally computes and visualizes the spreadsheet data flow graph. The audience will be invited to suggest interesting spreadsheet analyses and transformations that might be implemented with this infrastructure.
This is a sneak preview of the student presentation João will give at the Summer School on Advanced Functional Programming (Tartu, 21 august, 2004). GLR parsing is a generalization of LR parsing where ambiguous grammars do not lead to parse errors, but to several parsers working in parallel. We have implemented GLR in Haskell relying on lazy evaluation and incremental computation to improve its performance and approach closer to the original imperative formulation of the algorithm.
The data models of most legacy software systems are not explicitly defined. Instead, they are encoded in the program source code. Using a mixture of program understanding techniques it is possible to (partly) reconstruct these models. In this talk we provide details of a reverse engineering project carried out at the Software Improvement Group. In this project, the software portfolio of a large multinational bank, consisting of many million lines of Cobol code, was analyzed. Both hierarchical databases (IMS) and relational ones (DB2) are used in this portfolio. We will survey the program understanding techniques used, and detail the particular challenges posed by the size and heterogeneity of the analyzed portfolio.
Datatype invariants are a significant part of the business logic which is at the heart of any commercial software application. However, invariants are hard to maintain consistent and their formal verification requires costly «invent and verify» procedures, most often neglected throughout the development life-cycle. We sketch a basis for a calculational approach to maintaining invariants based on a «correct by construction» development principle. We propose that invariants take the place of data-types in the diagrams that describe computations and use weakest liberal preconditions to type the arrows in such diagrams. All our reasoning is carried out in the relational calculus structured by Galois connections.
Parser combinators elegantly and concisely model generalised LL parsers in a purely functional language. They nicely illustrate the concepts of higher-order functions, polymorphic functions and lazy evaluation. Indeed, parser combinators are often presented as "the" motivating example for functional programming. Generalised LL, however, has an important drawback: it does not handle (direct nor indirect) left recursive context-free grammars. In a different context, the (non-functional) parsing community has been doing a considerable amount of work on generalised LR parsing. Such parsers handle virtually any context-free grammar. Surprisingly, no work has been done on generalised LR by the functional prog. community. In this talk, I will present a concise (100 lines!), elegant and efficient implementation of an incremental generalised LR parser generator/interpreter in Haskell. Such parsers rely heavily on lazy evaluation. Incremental evaluation is obtained via function memoisation. I will present the HaGlr tool: a prototype implementation of our generalised LR parser generator. The profiling of some (toy) examples will be discussed.
The basic motivation of component based development is to replace conventional programming by the composition and configuration of reusable off-the-shelf units externally coordinated, through a network of connecting devices, to achieve a common goal. This work introduces a new relational model for connectors of software components. The proposed model adopts a coordination point of view in order to deal with components temporal and spatial decoupling and, therefore, to provide support for looser levels of inter-component dependency and effective external control.
A Unified Approach for the Integration of Distributed Heterogeneous Software Components
Barrett Bryant
A framework is proposed for assembling software systems from distributed heterogeneous components. For the successful deployment of such a software system, it is necessary that its realization not only meets the functional requirements but also non-functional requirements such as Quality of Service (QoS) criteria. The approach described is based on the notions of a meta-component model called the Unified Meta Model (UMM), a generative domain model, and specification of appropriate QoS parameters. A formal specification based on Two-Level Grammar is used to represent these notions in a tightly integrated way so that QoS becomes a part of the generative domain model. A simple case study is described in the context of this framework.
In this talk, I will give a brief overview of Haskell software development around the world and I will present a light-weight infrastructure to support such development by us. Among other things, I will talk about development tools such as Haddock, QuickCheck, HUnit, and GHood. I will point out some nice development projects that seem relevant to the Research.PURe project, such as the refactoring project in Kent.
Functional programs are particularly well suited to formal manipulation by equational reasoning. In this setting, it is straightforward to use calculational methods for program transformation. Well-known transformation techniques, like tupling or the introduction of accumulating parameters, can be implemented using calculation through the use of the fusion (or promotion) strategy. In this paper we revisit this transformation method, but, unlike most of the previous work on this subject, we adhere to a pure point-free calculus that emphasizes the advantages of equational reasoning. We focus on the accumulation strategy initially proposed by Bird, where the transformed programs are seen as higher-order folds calculated systematically from a specification. The machinery of the calculus is expanded with higher-order point-free operators that simplify the calculations. A substantial number of examples (both classic and new) are fully developed, and we introduce several shortcut optimization rules that capture typical transformation patterns.
Functional transposition is a technique for converting relations into functions aimed at developing the relational algebra via the algebra of functions. This talk attempts to develop a basis for generic transposition. Two well-known instances of the construction are considered, one applicable to any relation and the other applicable to simple relations only. Our illustration of the usefulness of the generic transpose takes advantage of the free theorem of a polymorphic function. We show how to derive laws of relational combinators as free theorems of their transposes. Finally, we relate the topic of functional transposition with the hash-table technique for data representation.
Members of the Research.PURe team seem to see in sorting algorithms a never-ending source of inspiration. In this session JoseBarros and ManuelBernardoBarbosa will explain why they think program-understanding can help optimize sorting algorithms, and JorgeSousaPinto will discuss how all major functional sorting algorithms can be derived from insertion sort.
We will explain the basics of collaborative web editing with Wiki. We will discuss the way we have organized our local Wiki and invite you to contribute to it. Finally we will exchange ideas about how to use the Wiki for our research and education.
March, 25 The lambda-coinduction by calculation stuff was presented today in Wien by AlexandraSilva as a short communication to CMCS'06.
March, 24 A paper on Slicing by Calculation (NunoRodrigues and LuisSoaresBarbosa) and another one on Generic Process Algebra (Paula Ribeiro, MarcoAntonioBarbosa and LuisSoaresBarbosa) accepted for SBLP'06 (acceptance rate: 35%).
March, 20 Research.PURe Year 2 Progress Report was released. Once again the project performance was very good: 4 journal papers (1 was expected), 9 conference papers (5 expected), 1PhD thesis and 2 MSc dissertations.
March, 9 A technical report by Alcino Cunha, José Nuno Oliveira, and Personal.Joost Visser entitled Type-safe Two-level Data Transformation is available here.
Jan, 23 A paper by Personal.Joost Visser entitled Structure Metrics for XML Schema will be presented at XATA2006.
Jan, 6 The paper by by AlcinoCunha, JorgeSousaPinto, and JoseProenca presented in September at the IFL'05 Workshop has been accepted for publication in the Revised Papers (Springer LNCS).
2005
Dec, 9 A paper by Miguel Cruz, LuisSoaresBarbosa and JoseNunoOliveira, entitled From Algebras to Objects: Generation and Composition was published today in the Journal of Universal Computer Science (vol 11 (10)).
Dec, 3 A paper by Personal.Joost Visser entitled Matching Objects without Language Extension was accepted for publication in the Journal of Object Technology.
Nov, 14NunoRodrigues participated in the Schloss Dagstuhl Seminar 05451 on "Beyond Program Slicing", presenting a
paper on "Calculating Functional Slices". His group received the Best Presentation Award.
Sep, 19 Paper accepted at FACS'05 on Component Identification Through Program Slicing (by NunoRodrigues and LuisSoaresBarbosa).
August 15 II Research.PURe Workshop scheduled for 11-12 October, 2005. Invited speaker: Jeremy Gibbons (Oxford)
July 20 Paper accepted at ICTAC 2005 on Refinement of Software Architectures (by Sun Meng, LuisSoaresBarbosa and Zhang Naixiao).
April 9 Paper accepted at FM 2005 on VooDooM (by TiagoAlves, PauloSilva, JoseNunoOliveira, and JoostVisser).
April 5 The first distribution of the UMinho Haskell Software was released.
Mar 21 The PUReCafe slot will open each Tuesday on 12:00 (was 11:00).
Jan 17 Good News: The expected number of publications in the original Research.PURe proposal for
the fisrt year has been largely surpassed (5 expected vs 11 published + more 5 accepted).
More details on the project performance can be read on the Y1 Progress Report.
2004
Sep 27 Various tools from PUReSoftware are now available online.
Sep 26 The PUReCafe slot was moved to Tuesday's between 11:00 and 13:00.
Sep 20 The EVENTS topic was updated with information on the workshop. Authors: please upload your slides!
Sep 7 2nd Announcement and Programme: First Project Workshop, 13-14 September 2004
Aug 25 Research.PURe paper accepted at ICTAC2004 on coalgebraic models for software connectors (by MarcoAntonioBarbosa and LuisSoaresBarbosa).
July 26 Call for Participation: First Project Workshop, 13-14 September 2004
June 17 Matthijs Kuiper, main developer of the LRC attribute grammar system, will be visiting the department in the week of June 21-25.
June 4 Another date for all Research.PURe people: First Project Workshop scheduled for 13-14 September. Alberto Pardo (Uruguay) is an invited speaker.
June 4 First Research.PURe Seminar on Algebras of Program Construction by R. Backhouse, 21-22 June
June 3 Research.PURe paper accepted at CTCS2004 on the semantics of UML components (by LuisSoaresBarbosa, Sun Meng, B. Aichernig and Zhang Naixiao).
On the Specification of a Component Repository, Rodrigues, N. and Barbosa, L., FACS'03 (Int. Workshop on Formal Aspects of Component Software), FME, Pisa. September, 2003. (pdf)
Automatic Visualization of Recursion Trees: a Case Study on Generic Programming, Cunha, A., WFLP'03 (12th International Workshop on Functional and (Constraint) Logic Programming). In volume 86.3 of ENTCS: Selected papers of WFLP'03. 2003. (pdf)
Towards a Relational Model for Component Interconnection, Barbosa, M. A. and Barbosa, L. SBLP'04, Niteroi. May, 2004.
On Refinement of Generic Software Components, Meng, S. and Barbosa, L., AMAST'04 (10th Int. Conf. on Algebraic Methods and Software Technology), Stirling, August, 2004 (Best Student Co-authored Paper Award). Springer LNCS 3116 (pag. 506 - 520).
Transposing Relations: from Maybe Functions to Hash Tables, Oliveira J.N and Rodrigues C.J., MPC'04 (Int. Conf. on the Mathematics of Program Construction), Stirling, August 2004, Springer LNCS 3125 (pag. 334-356).
A Coalgebraic Semantic Framework for Component Based Development in UML, Meng, S. and Aichernig, B. and Barbosa, L. and Naixiao, Z., CTCS'04 (Int. Conf. on Category Theory and Computer Science), Copenhagen. August, 2004 (to appear ENTCS)
Design, Implementation and Animation of Spreadsheets in the Lrc System, João Saraiva, FoS'04 (Int. Workshop on Foundations of Spreadsheets), Rome, Italy, September, 2004 (to appear ENTCS) http://www.di.uminho.pt/~jas/Research/Papers/FOS04/divs.ps.gz
On Semantics and Refinement of Statecharts: A Coalgebraic View, Meng, S. and Naixiao, Z and Barbosa, L., II SEFM (2nd IEEE International Conference on Software Engineering and Formal Methods), Beijing. September, 2004. IEEE Computer Society Press.
Bounded Version Vectors, Almeida J. B. and Almeida P. S. and Baquero C., Proceedings of DISC 2004 (18th International Symposium on Distributed Computing), Springer-Verlag LNCS 3274 (pag. 102 - 116). October, 2004.
Specifying Software Connectors, Barbosa, M. A. and Barbosa, L. ICTAC'04 (to appear in Springer LNCS), Guyang, China, September, 2004.
Functional Programming and Program Transformation with Interaction Nets, Mackie I., Pinto J.S, Vilaça M. In preliminary proceedings of International Symposium on Logic-based Program Synthesis and Transformation (LOPSTR 2005).
A Framework for Point-free Program Transformation, Alcino Cunha, Jorge Sousa Pinto and José Proença. In Revised Proceedings of the 17th International Workshop on Implementation and Application of Functional Languages (IFL'05). To appear in Springer LNCS.
Structure Metrics for XML Schema, Joost Visser. Proceedings of XATA2006.
A Local Graph-rewriting System for Deciding Equality in Sum-product Theories, José Bacelar Almeida, Jorge Sousa Pinto, and Miguel Vilaça. In Proceedings of the Third Workshop on Term Graph Rewriting (TERMGRAPH 2006), Vol. 176(1) Electronic Notes in Theoretical Computer Science, pags. 139-163, 2007.
Strongly Typed Rewriting For Coupled Software Transformation, Alcino Cunha, Joost Visser. In Proceedings of RULE 2006, ENTCS, to appear.
Strong Types for Relational Databases, Alexandra Silva and Joost Visser. In Proceedings of Haskell Workshop 2006, to appear.
Publications (Journal Papers and Book Chapters)
A Relational Model for Component Interconnection, Barbosa, M. A. and Barbosa, L., Jour. Universal Computer Science, 10 (7), pag. 808-823, 2004.
(accepted) On the Semantics of Componentware: A Coalgebraic Perspective, Barbosa, L. and Meng, S. and Aichernig, B. and Rodrigues, N., chapter in "Mathematical Frameworks for Component Software - Models for Analysis and Synthesis", Jifeng He and Zhiming Liu (eds), Review Volume in the Series on Component-Based Development, World Scientific. 2004.
(accepted) Components as Coalgebras: the Refinement Dimension, Sun Meng and Barbosa, L., Theor. Computer Science, Elsevier, 2004.
Point-free Program Transformation, Cunha, A. and Pinto, J.S., Fundamenta Informaticae Volume 66, Number 4 (Special Issue on Program Transformation), April-May 2005, IOS Press, 2005.
Object Matching without Language Extension, Joost Visser, Journal of Object Technology, accepted for publication in the Nov/Dec 2006 issue.
Generalized LR Parsing in Haskell, João Fernandes, DI-Research.PURe-04.11.01, November 2004. (pdf)
Conversão de Código Pointwise para Código Pointfree, José Vilaça, DI-Research.PURe-04.11.02, November 2004. (pdf)
Functional dependency theory made 'simpler', J.N. Oliveira, DI-Research.PURe-05.01.01, January 2005. (pdf)
Tranformações pointwise - point-free, José Proença, DI-Research.PURe-05.02.01, February 2005. (pdf)
Development of an Industrial Strength Grammar for VDM, Tiago Alves and Joost Visser, DI-Research.PURe-05.04.29, April 2005. (pdf)
Metrication of SDF Grammars, Tiago Alves and Joost Visser, DI-Research.PURe-05.05.01, May 2005. (pdf)
Functional Programming and Program Transformation with Interaction Nets, Ian Mackie, Jorge Sousa Pinto and Miguel Vilaça, DI-Research.PURe-05.05.02, May 2005 (pdf)
Down with Variables, Alcino Cunha, Jorge Sousa Pinto, and José Proença, DI-Research.PURe-05.06.01, June 2005 (pdf)
Point-free Simplification, José Proença, DI-Research.PURe-05.08.01, August 2005. (pdf)
ProveIt - An interactive point-free proof editor, José Pedro Correia, DI-Research.PURe-05.08.02, August 2005. (pdf)
A Local Graph-rewriting System for Deciding Equality in Sum-product Theories, José Bacelar Almeida, Jorge Sousa Pinto, and Miguel Vilaça. DI-Research.PURe-06.02.01, February 2006 (revised in June 2006). (pdf)
Type-safe Two-level Data Transformations -- with appendix on derecursivation and dynamic typing, Alcino Cunha, José Nuno Oliveira, Joost Visser. DI-Research.PURe-06.03.01, March 2006. (pdf)
A Tool for Programming with Interaction Nets, José Bacelar Almeida, Jorge Sousa Pinto and Miguel Vilaça. DI-Research.PURe-06.04.01, April 2006. (pdf)
Deriving Sorting Algorithms, José Bacelar Almeida, Jorge Sousa Pinto. DI-Research.PURe-06.04.02, April 2006. (pdf)
Report Publication
Next report number: DI-Research.PURe-06.04.03 (please update on uploading a new report: YY.MM.nn, nn being sequential inside each month)
The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that is being developed in the context of various research and educational projects. The objective is to enable use and reuse of software accross project boundaries. In particular, software developed in the context of the Research.PURe Project, is collected into the UMS repository.
The UMS repository is roughly partitioned into two parts:
Libraries: a hierarchical library of reusable modules.
Tools: a collection of tools.
The libraries offer reusable functionality. Each tool bundles part of the library functionality behind an interactive or command-line interface.
If you want to contribute, please consult UsingCVS.
The UMinho Haskell Libraries
The UMinho Haskell Libraries are located in the libraries subdirectory. The modules included in the libraries cover a wide range of functionality, for instance:
Data.Relation: Representation and operations on relations. A special case of relations are graphs. The operations include graph chopping and slicing, strong connected component analysis, graphs metrics, and more.
Language.Gnumeric: Support for analysis and manipulation of spreadsheets.
Language.Java: Support for analysis and manipulation of Java programs.
Pointless: Support for pointfree programming.
Camila: Support for VDM like concepts, such as data type invariants, pre- and post-conditions, and more.
For a complete overview, see the online API documentation for version 1.0, generated with Haddock. In the distribution, the API documentation can be found in the subdirectory libraries/documentation.
The libraries subdirectory contains a Makefile that allows you to easily do various things, among which:
make ghc
compile all library modules with GHC
make ghci
load all library modules into GHCi
make haddock
generate library documentation with Haddock
make dist
generate a distribution of the library
make hunit
run HUnit on all test modules
make quickCheck
run quickCheck on all library modules
make ghood
generate GHood applets
If you want to operate on just a part of the library, you can do that by overriding the Makefile's top
variable, for instance as follows:
make top=Data/Relation ghci
And likewise for any other target. Consult the Makefile for other variables that can be overridden.
The UMinho Haskell Tools
Several tools are included in the UMS distributions, among which:
Pointless Haskell is library for point-free programming with recursion patterns defined as hylomorphisms. It is part of the UMinho Haskell Libraries that are being developed in the Research.PURe project. The core of the library is described in the following paper.
It also allows the visualization of the intermediate data structure of the hylomorphisms with GHood. This feature toghether with the DrHylo tool allows us to easily visualize recursion trees of Haskell functions. We first implemented this ideas using Generic Haskell, as presented in WFLP'03. We now take a different approach to genericity based on Personal/Alcino.PolyP.
Point-free definitions of uncurried versions of the basic combinators.
Pointless.Isomorphisms
Auxiliary isomorphism definitions.
Pointless.Functors
Definition of functors, generic maps, and sum-of-products representation.
Pointless.RecursionPatterns
Definition of the typical recursion as hylomorphisms.
Pointless.Observe.Functors
Definition of generic observations.
Pointless.Observe.RecursionPatterns
Recursion patterns with observation of intermediate data structures.
Pointless.Examples.Examples
Lots of examples.
Debug.Observe
Slightly modified GHood library.
Usage
For the moment there is no documentation, but by reading the papers and looking at examples you should be able to learn it by yourself. It was only tested on GHC. I think that it should be easy to use it under Hugs.
Please send feedback to alcino@di.uminho.pt.
Tool for deriving hylomorphisms from a restricted Haskell syntax. It is based on the algorithm first presented in the paper Deriving Structural Hylomorphisms From Recursive Definitions at ICFP'96 by Hu, Iwasaki, and Takeichi.
This is a project where I, José Proença, worked on since April until October 2005. It was supervised by Jorge Sousa Pinto and Alcino Cunha, who supported and helped me during this time. The proposal is explained in more detailed in here. The results can be found in my internship report, here.
The project consists on two parts:
Definition of two refactorings -- the conversion from point-wise to pointfree and the removal of guards;
Automatic simplification and transformation of pointfree expressions.
Refactorings in HaRe
In the begining of the project, I spent two weeks in Canterbury developing two refactorings to be part of HaRe:
A snapshot of the source code where these transformations are applied can be found here.
There are also some examples that can be found in the following links:
Allows for the automatic simplification and some program transformation of Haskell code, written in a point-free style. The technical report is available here. The SimpliFree tool is now available in the Uminho Haskell Libraries, that can be downloaded from the CVS repository.
This tool uses Haskell pattern matching to apply rules, by creating an auxiliary file with the functions where the strategies, rules and the pointfree terms are defined. In spite of the fact that this approach meant to be simpler than most approaches where a pattern matching algorithm is defined, the definitions of functions that apply a rule were more complex than expected.
In September, this tool, together with the DrHylo tool and the Pointless library, were presented in IFL'05 workshop.
The presentation "A Framework for Point-free Program Transformation", shown in this workshop, can be found here.
The SimpliFree tool was also presented in the PURe Workshop 2005. The slides can be found here.
In a situation in which the only quality certificate of the running software artifact still is life-cycle endurance, customers and software producers are little prepared to modify or improve running code. However, faced with so risky a dependence on legacy software, managers are more and more prepared to spend resources to increase confidence on - i.e. the level of understanding of - their code.
As a research area, program understanding affiliates to reverse engineering, understood as the analysis of a system in order to identify components and intended behaviour to create higher level abstractions of the system.
If forward software engineering can today be regarded as a lost opportunity for formal methods (with notable exceptions in areas such as safety-critical and dependable computing), its converse still looks a promising area for their application. This is due to the complexity of reverse engineering problems and exponential costs involved.
In such a setting, this project intends to develop calculi for program understanding and reverse engineering, building on the formal techniques developed by academics for the production of fresh, high quality software. One of its fundamental goals is to show that such techniques, eventually merged with other, informal program maintenance and debugging procedures, will see the light of (industrial) success in their reverse application to pre-existing code.
The project addresses the areas of program reengineering, classification and refinement. The envisaged notion of a `program' is broad enough to include typical data-processing applications, real-time algorithms or component-based services. As an increasing number of systems are based on the cooperation of distributed, heterogeneous components organised into open software architectures, a particular emphasis is placed on the extension of classical techniques to the classification and reeginering of coordination middlewares. In each of these areas the project aims to develop specific techniques and calculi which, based on sound mathematical foundations, are scalable to the industrial practice and easily applicable by the working software engineer.
SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non-terminals, productions, and disambiguation constructs, McCabe's cyclometric complexity, and structure metrics such as tree impurity and normalized count of grammar levels.
The metrics implemented by SdfMetz are explained and illustrated in:
Tiago Alves and Joost Visser, Metrication of SDF Grammars. Technical Report, DI-Research.PURe-05.05.01, Departamento de Informática, Universidade do Minho, May 2005. pdf
Fig 1: Scatterplot of non-terminal count versus Halstead size metrics.
This technical report also shows metric values for 27 non-trivial grammars, and some discussion of the interpretation of this data. Some exerpts from the report are included below. A companion tool SdfCoverage, for measuring grammar coverage is also mentioned in the report.
SdfMetz is intended to be an instrument for Grammar Engineering. An overview of research into grammar engineering can be found in:
P. Klint and R. Lämmel and C. Verhoef, Towards an engineering discipline for grammarware, link.
In particular, SdfMetz is inspired by
James F. Power and Brian A. Malloy, A metrics suite for grammar-based software, link.
We have adapted their suite of metrics to the SDF grammar notation, and extened it with a few SDF-specific metrics. Also, the SdfMetz tool supports generation of immediate and transitive successor graphs from SDF grammars. For details, see the technical report Metrication of SDF grammars.
SDF stands for Syntax Definition Formalism. It is a purely declarative (no semantic actions) and modular grammar notations which is supported by Generalized LR Parsing. For information and resources regarding SDF, see:
The initial motivation for the development of the SdfMetz tool came from a grammar development project where an SDF grammar for the VDM-SL language was recovered from an ISO reference manual. A description of the use of SdfMetz for monitoring that grammar development process can be found in:
Tiago Alves and Joost Visser, Grammar-centered Development of VDM Support. In proceedings of the Overture Workshop, colocated with Formal Methods 2005. Technical Report of the University of Newcastle, to appear, 2005. pdf
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. pdf
The deliverable of that project, a VDM-SL front-end, can be found on the VooDooMFront web page.
Features
Fig 2: Immediate successor graph of a fragment of the VDM-SL grammar.
Fig 3: Transitive successor graph of the same fragment of the VDM-SL grammar.
SdfMetz is a command line tool. For details about its usage, type SdfMetz -h at the command line prompt.
Input
SdfMetz accepts one of more SDF grammar files as input.
Alternatively, SdfMetz accepts grammars in Semantic Designs' DMS grammar notation.
Output
The metric values computed by SdfMetz can be exported as a nicely formatted textual report, or as comma-separated-value files, for easy import into e.g. Excel or SPSS.
SdfMetz calculates immediate and transitive successor graphs to compute structure metrics. These graphs can also be exported, in the dot format of AT&T's GraphViz'.
In addition, SdfMetz can export the non-singleton levels of the input grammars. These are groups of non-terminals that are mutually reachable from each other in the grammar's successor graph.
Computed metrics
The suite of metrics computed by SdfMetz is defined and explained in the technical report Metrication of SDF grammars. They include counters for non-terminals, terminals, productions, and disambiguations constructs, McCabe's cyclometeric complexity, and structure metrics such as tree impurity and normalized count of levels.
A grammar comparison experiment
As an initial experimant in grammar metrication, we have applied SdfMetz to collect metrics data for a range of grammars from various origins. Full details about this experiment can be found in the Section Data Collection in:
Tiago Alves and Joost Visser, Metrication of SDF Grammars. Technical Report, DI-Research.PURe-05.05.01, Departamento de Informática, Universidade do Minho, May 2005. pdf
Sampled grammars
The sampled grammars include 18 SDF grammars for languages such as Yacc, BibTex, Fortran, Toolbus, Stratego, SDF itself, Java, SDL, C, Cobol, DB2, PL/SQL, VDM-SL, and VB.Net. These grammars were obtained from the following sources:
sfi - Grammars freely available in the Strafunski bundle
In the report, metrics calculated by us are presented side by side with those of four BNF grammars from the paper A metrics suite for grammar-based software of Power and Malloy.
Raw data
The technical report presents the collected metrics data in a series of tables, one for each category of metrics. The raw data of the experiment is available upon request in a single comma-separated-value file.
A grammar monitoring experiment
Fig 4: Plot of three grammar metrics for 48 subsequent development versions.
The initial motivation for the development of the SdfMetz tool came from a grammar development project where an SDF grammar for the VDM-SL language was recovered from an ISO reference manual. A description of the use of SdfMetz for monitoring that grammar development process can be found in:
Tiago Alves and Joost Visser, Grammar-centered Development of VDM Support. In proceedings of the Overture Workshop, colocated with Formal Methods 2005. Technical Report of the University of Newcastle, to appear, 2005. pdf
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. pdf
The deliverable of that project, a VDM-SL front-end, can be found on the VooDooMFront web page.
Implementation
The SdfMetz tool was implemented in the functional programming language Haskell using the Strafunski bundle for generic traversal support.
The tool was developed using a grammar-centered approach, where various kinds of functionality were automatically generated from a concrete syntax definition of the SDF language (the SDF language specified in SDF). The parser was automatically generated with sdf2table, from the SDF bundle. The Haskell support for representing, and pretty-printing abstract syntax trees (ASTs) was automatically generated with Sdf2Haskell, from the Strafunski bundle. AST traversal and marshalling support was generated with the Strafunski-aware DrIFT tool.
The reusable functionality of SdfMetz has been organized as modules of the UMinho Haskell Libraries. The structure metrics and underlying graph algorithms have been implemented on a generic graph representation, available from these same libraries.
Download
The SdfMetz tool (version 1.1) is available for download in a self-contained distribution. (download)
As alternative, it can also be obtained as part of the UMinho Haskell Libraries & Tools.
Future work
Apart from adding more metrics to the repertoire of SdfMetz, we intend to do the following:
Add front-ends for Yacc and ANTLR grammars
Collect more grammars for experimentation
Perform more comprehensive statistical analysis on the collected data
The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering techniques to spreadsheets.
Spreadsheet tools can be viewed as programming environments for
non-professional programmers. These so-called ''end-user'' programmers include teachers, secretaries, physicists, biologists, accountants, managers, consultants. For all these people, who are not employed or trained as programmers, spreadsheets are more often than not the programming environment of choice.
In fact, end-user programmers vastly outnumber professional programmers. By some estimates, the number of end-user programmers in the U.S. alone is expected to reach 55 million by 2005, as compared to only 2.75 million professional programmers. Through the efforts of these people, huge numbers of large and often complex spreadsheets are created and maintained every day in all companies and public institutes around the world. For these organizations, spreadsheets represent business-critical assets with significant economic value.
Spreadsheets, like any other program, can unfortunately easily turn from asset into liability. Development, maintenance, and extension of spreadsheets is notoriously error-prone. It is difficult to grasp the logic encoded in a spreadsheet, especially when it is large and developed by others. It is difficult to test spreadsheets, to assess their quality, and to validate their correctness. In this sense, a legacy problem exists with respect to spreadsheets as much, or perhaps even more, as with respect to conventional programs.
This observation leads to the suggestion that techniques for program understanding and reverse engineering, could be likewise applied, in adapted form, to spreadsheets. Just as they are useful for dealing with legacy software in the conventional sense, so they could be useful for dealing with spreadsheet legacy.
In fact, spreadsheets, when viewed as programming language, can be characterized as a particularly low-level one. Their language of cell references and formulas offers only low-level expressiveness compared to regular programming languages. They offer no support for abstraction, encapsulation, or structured programming. For this reason, it is fair to state that spreadsheets could benefit even more from program understanding and reverse engineering techniques than conventional programs.
In this project, Martin Erwig, Robin Abraham and Margaret Burnett defined a unit system for spreadsheets that allows to reason about the correctness of formulas in concrete terms. The fulcral point of this project is the high flexibility of the unit system developed, both in terms of error reporting and reasoning rules, that increases the possibility of a high acceptance among end users.
Selected Publications
How to Communicate Unit Error Messages in Spreadsheets, Robin Abraham and Martin Erwig, 1st Workshop on End-User Software Engineering, 52-56, 2005 (pdf)
Header and Unit Inference for Spreadsheets Through Spatial Analyses, Robin Abraham and Martin Erwig, IEEE Int. Symp. on Visual Languages and Human-Centric Computing, 165-172, 2004 (pdf), Best Paper Award
Visually Customizing Inference Rules About Apples and Oranges, Margaret M. Burnett and Martin Erwig, 2nd IEEE Int. Symp. on Human Centric Computing Languages and Environments, 140-148, 2002 (pdf)
Adding Apples and Oranges, Martin Erwig and Margaret M. Burnett, 4th Int. Symp. on Practical Aspects of Declarative Languages, LNCS 2257, 173-191, 2002 (pdf)
Spreadsheets are likely to be full of errors and this can cause organizations to lose millions of dollars. However, finding and correcting spreadsheet errors is extremly hard and consumes a lot of time.
Probably inspired in database systems (personal guess) and how database management systems (DBMS) mantain the database consistent after every update and transaction, Martin Erwig, Robin Abraham, Irene Cooperstein and Steve Kollmansberger designed and implemented Gencel. Gencel is an extension to Excel, based on the concept of a spreadsheet template, which captures the essential structure of a spreadsheet and all of its future evolutions. Such a template ensures that every update is safe, avoiding reference, range and type errors.
Templates can be created with the editor ViTSL, similar to Excel (with additional features to design templates).
Selected Publications
Gencel: A Program Generator for Correct Spreadsheets, Martin Erwig and Robin Abraham and Irene Cooperstein and Steve Kollmansberger, Journal of Functional Programming, 2005, to appear (pdf)
Visual Specifications of Correct Spreadsheets, Robin Abraham, Martin Erwig, Steve Kollmansberger, and Ethan Seifert, IEEE Int. Symp. on Visual Languages and Human-Centric Computing, 2005, to appear (pdf)
Automatic Generation and Maintenance of Correct Spreadsheets, Martin Erwig, Robin Abraham, Irene Cooperstein, and Steve Kollmansberger, 27th IEEE Int. Conf. on Software Engineering, 136-145, 2005 (pdf)
Goal-Directed Debugging of Spreadsheets, Robin Abraham and Martin Erwig, VLHCC '05: Proceedings of the 2005 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC'05), 2005 (pdf)
Simon Peyton Jones, together with Margaret Burnett and Alan Blackwell, describe extensions to Excel that allow to integrate in the spreadsheet grid user-defined functions. That take us from a end-user programming paradigm to an extended system, which provides some of the capabilities of a general programming language.
Selected Publications
A user-centred approach to functions in Excel. Simon Peyton Jones, Margaret Burnett, Alan Blackwell. Proc International Conference on Functional Programming, Uppsala, Sept 2003 (ICFP'03), pp 165-176, 12 pages. (pdf)
Champagne Prototyping: A Research Technique for Early Evaluation of Complex End-User Programming Systems. Alan Blackwell, Margaret Burnett, Simon Peyton Jones. 12 pages, March 2004. (pdf)
José Nuno Oliveira describes a pointfree calculus and refinement laws for spreadsheet normalization.
He shows how a binary representation of an n-ary relation makes sense in database theory context, and how lengthy formulae can become very simple and elegant. As an example, it follows the definition of functional dependency satisfiability in the two calculus:
Pointwise calculus (classical)
Pointfree calculus
Selected Publications
Functional dependency theory made 'simpler', J.N. Oliveira, Technical report, DI-Research.PURe-05.01.01, January 2005. (pdf)
Our project
Research plan
The project proposal for which a BIC grant has been awarded is available:
In this proposal the following deliverables are expected:
A Spreadsheet Transformation and Analysis API -- Develop a Haskell library that supports the processing of spreadsheets. The functionality offered by this library should include: (1) conversion of spreadsheets to and from XML, including structured representation of formulas. (2) marshaling between the XML repre- sentation of spreadsheets and the strongly-typed Haskell representation. (3) functions for querying and transforming the various elements of the Haskell representation. The Spreadsheet API should become part of the UMinho Haskell Library initiative.
A Spreadsheet Type Reconstruction Component -- Based on the above API, implement an algorithm for reconstruction of types in a spreadsheet. The algorithm analysis the use of cells in formulas, and computes type and sub-type relations between cells. This component will be useful for testing purposes and error detection in spreadsheets.
A Relational Data Model Extraction Component -- Based on the Spreadsheet API, implement an algorithm for extraction of the underlying data model of a spreadsheet. In particular, the algorithm detects which cells are used as identifying keys. Based on this, a relational data model will be inferred, including primary keys, foreign key relationships and integrity constrains. This component will be useful to support migration from spreadsheets solutions to databases solutions in industrial contexts.
Spreadsheet Quality Assessment Case Study -- The developed components for type reconstruction and data model extraction will be applied to a set of commercially used spreadsheets with the ob jective of quality assessment. In particular, they will be used to detect errors, and uncover the underlying data model of the involved spreadsheets. The results and the methodology of the quality assessment will be described in a spreadsheet quality assessment report.
Possible integration with other projects
To promote the adoption of the Gencel system, tools that extract specifications from arbitrary spreadsheets are needed.
Deliverable 3, based on José Nuno Oliveira's research, could be a nice tool to integrate with Gencel.
For read only access you can use the username anonymous (password anonymous).
For read-write access, you should be a member of the PUReCvsGroup? (contact an
administrator for that) and use the twiki name and password.
Check out the repository
With:
cvs -d :pserver:username@haskell.di.uminho.pt:/mnt/ds/cvsroot checkout PURe
This gives you a directory Research.PURe with subdirectories such as software and papers. This is your local copy of the repository.
Update your local copy
Change to any directory within your local copy of the repository, and update it with:
cvs upd -dP
The -dP options tell CVS to also synchronize subdirectories, if they are non-empty.
Add files
If you create new files or directories in your local copy, and you can register them for addition with:
cvs add filename
This does not yet store the file in the repository. You still need to commit it (see below).
Commit local modifications into the repository
After making modifications in you local copy (changing or adding files) you can commit them to the repository as follows:
cvs commit
Note
For all this to work, you need an environment variable CVS_RSH set to ssh such that cvs will make a connection with the server on which the repository resides via ssh.
VooDooM: A transformation tool for VDM-SL.
FUNCTIONALITYVooDooM reads VDM-SL specifications and applies transformation rules to
the datatypes that are defined in them to obtain a relational
representation for these datatypes. The relational representation can be
exported as:
VDM-SL datatypes (inserted back into the original specification)
SQL table definitions (can be fed to a relational DBMS)
USAGE
Just type VooDooM at the command line, and follow instructions.
IMPLEMENTATIONVooDooM makes use of the parsing, pretty-printing, and traversal support for VDM-SL provided by VooDooMFront. This means that VooDooM uses a VDM-SL grammar specified in SDF together with Haskell modules generated from this grammar using the Sdf2Haskell? tool of the Strafunski bundle.
DOCUMENTATION
The relational calculus implemented by VooDooM is described in the following paper:
In addition to the calculus itself, the paper descibes the use of strategic programming in its implementation, using the Haskell-based Strafunski bundle.
The grammar is based on the ISO/IEC 13817-1:1996 reference document that describes the concrete and abstract syntax of VDM-SL.
Documentation
Technical Report: Development of an Industrial Strength Grammar for VDM
The development of the VDM grammar in SDF is documented in the following technical report:
Tiago Alves and Joost Visser, Development of an Industrial Strength Grammar for VDM. Technical Report, DI-Research.PURe-05.04.29, Departamento de Informática, Universidade do Minho, April 2005. (pdf)
The report describes the grammar engineering methodology that was applied, the tools employed, and the various stages of evolution during grammar development. In particular, the report shows metrics data collected using SdfMetz for all 48 development versions of the grammar. A pretty-printed version of the grammar is included as appendix.
Browsable grammar
A browsable HTML rendering of the VDM-SL grammar in SDF is available from:
By clicking on non-terminal names one can easily navigate and explore the grammar structure.
Extreme Grammaring Presentation
Although parsing is a subset of a well studied area like compilers, grammars were always looked upon as "the ugly duckling".
In this presentation I propose a novel methodology, baptized "Extreme Grammaring", for developing grammars using the SDF (Syntax Definition Formalism), inspired in Extreme Programming.
This methodology made possible the development of an industrial strength grammar for ISO VDM-SL, one of the most common languages used for formal specification.
"Extreme Grammaring" presentation slides (Presented on December, 21 in the PUReCafe)
Haskell front-end with parsing, AST outputting and pretty-printing support.
For detailed description of each release, see the remarks below as well as the README and ChangeLog files included in each distribution.
See VDMGrammarEvolution for metric values for all versions.
Upcoming releases
Version 2.0: This version will contain the front-end for Java, supporting parsing, tree building, and tree traversal, most probably following the JJForester approach.
Related
VooDooM is a tool that converts VDM-SL data types to relational form, and exports them as SQL.
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ...
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ...
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ...
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ...
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ...
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ...
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ...
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ...
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ...
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ...
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ...
Sep 18 Paper Towards a Coordination Model for Interactive Systems by MarcoAntonioBarbosa, JoseCampos and LuisSoaresBarbosa has been accepted for FMIS'06 (Macau ...
TWiki.Research/PURe Web Preferences The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site level preferences ...
Spreadsheet Understanding The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering ...
One of the research topics of the Research.PURe Project is development of generic program slicing techniques. Contributors Personal.Nuno Rodrigues Patrick ...
UMinho Haskell Software Libraries Tools The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that ...
Using CVS For the current state of affairs you can take a peek at our repository. To use CVS do the following: Login to the repository With: cvs d :pserver:username ...
News May 18, 2005 A browsable version of the VDM SL grammar is now online. April 29, 2005 A report came out on the development of the VDM grammar in SDF. February ...
Haskell Activities and Communities Report Entries submitted by the LMF group at the Informatics Department of the University of Minho. Libraries 1. Pointless Haskell ...
This is a subscription service to be automatically notified by e mail when topics change in this Research/PURe web. This is a convenient service, so you do not have ...
VooDooM : A transformation tool for VDM SL. FUNCTIONALITY VooDooM reads VDM SL specifications and applies transformation rules to the datatypes that are defined ...
body { background color : lightgray; font family: Verdana, Arial, Helvetica, sans serif; font size: 12px ; } a:link { text decoration : none ; color : darkblue ...
What is ChopaChops? ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection: JReach ...
This page lists links to papers mentioned in the FCT proposal entitled "Software Analysis Lab": 1. http://www.di.uminho.pt/~joost.visser/publications/AToolBasedMethodologyForSoftwarePortfolioMonitoring ...
Program Understanding and Re-engineering: Calculi and Applications
The aim of the PURe research project is to develop calculi for program understanding and re-engineering. Formal techniques that have traditionally been developed for and applied to forward engineering of software, are applied in reverse direction, i.e. for the understanding and re-engineering of existing (legacy) program code. Read more.
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ...
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ...
What is ChopaChops? ChopaChops is a collection of tools for slicing and chopping of graphs. Currently, only a single tools is included in the collection: JReach ...
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ...
body { background color : lightgray; font family: Verdana, Arial, Helvetica, sans serif; font size: 12px ; } a:link { text decoration : none ; color : darkblue ...
One of the research topics of the Research.PURe Project is development of generic program slicing techniques. Contributors Personal.Nuno Rodrigues Patrick ...
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ...
Haskell Activities and Communities Report Entries submitted by the LMF group at the Informatics Department of the University of Minho. Libraries 1. Pointless Haskell ...
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ...
Sep 18 Paper Towards a Coordination Model for Interactive Systems by MarcoAntonioBarbosa, JoseCampos and LuisSoaresBarbosa has been accepted for FMIS'06 (Macau ...
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ...
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ...
UMinho Haskell Software Libraries Tools The UMinho Haskell Software is a repository of software, written in the functional programming language Haskell, that ...
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ...
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ...
This page lists links to papers mentioned in the FCT proposal entitled "Software Analysis Lab": 1. http://www.di.uminho.pt/~joost.visser/publications/AToolBasedMethodologyForSoftwarePortfolioMonitoring ...
Spreadsheet Understanding The Spreadsheet Understanding is a subproject of the Research.PURe project that aims to apply program understanding and reverse engineering ...
Using CVS For the current state of affairs you can take a peek at our repository. To use CVS do the following: Login to the repository With: cvs d :pserver:username ...
VooDooM : A transformation tool for VDM SL. FUNCTIONALITY VooDooM reads VDM SL specifications and applies transformation rules to the datatypes that are defined ...
News May 18, 2005 A browsable version of the VDM SL grammar is now online. April 29, 2005 A report came out on the development of the VDM grammar in SDF. February ...
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ...
This is a subscription service to be automatically notified by e mail when topics change in this Research/PURe web. This is a convenient service, so you do not have ...
TWiki.Research/PURe Web Preferences The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site level preferences ...
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ...
This is a subscription service to be automatically notified by e-mail when topics change in this Research/PURe web. This is a convenient service, so you do not have to come back and check all the time if something has changed. To subscribe, please add a bullet with your WikiName in alphabetical order to this list:
Format: <space><space><space>, followed by: * Main.yourWikiName (if you want that the e-mail address in your home page is used) * Main.yourWikiName - yourEmailAddress (if you want to specify a different e-mail address) * Main.anyTWikiGroup (if you want to notify all members of a particular TWikiGroup)
Related topics:TWikiUsers, TWikiRegistration
The following settings are web preferences of the TWiki.Research/PURe web. These preferences overwrite the site-level preferences in TWikiPreferences, and can be overwritten by user preferences (your personal topic, i.e. TWikiGuest in the TWiki.Main web)
Preferences:
If yes, set SITEMAPLIST to on, do not set NOSEARCHALL, and add the "what" and "use to..." description for the site map. Make sure to list only links that include the name of the web, e.g. Research/PURe.Topic links.
Set SITEMAPLIST = on
Set SITEMAPWHAT = PURe
Set SITEMAPUSETO = Program Understanding and Re-engineering: Calculi and Applications
Exclude web from a web="all" search: (Set to on for hidden webs)
Set NOSEARCHALL =
Default template for new topics and form(s) for this web:
WebTopicEditTemplate? : Default template for new topics in this web. (Site-level is used if topic does not exist)
Web preferences that are not allowed to be overridden by user preferences:
Set FINALPREFERENCES = WEBTOPICLIST, DENYWEBVIEW, ALLOWWEBVIEW, DENYWEBCHANGE, ALLOWWEBCHANGE, DENYWEBRENAME, ALLOWWEBRENAME
Notes:
A preference is defined as: 6 spaces * Set NAME = value Example:
Set WEBBGCOLOR = #FFFFC0
Preferences are used as TWikiVariables by enclosing the name in percent signs. Example:
When you write variable %WEBBGCOLOR% , it gets expanded to #CCCCCC .
The sequential order of the preference settings is significant. Define preferences that use other preferences first, i.e. set WEBCOPYRIGHT before WIKIWEBMASTER since %WEBCOPYRIGHT% uses the %WIKIWEBMASTER% variable.
You can introduce new preferences variables and use them in your topics and templates. There is no need to change the TWiki engine (Perl scripts).
TWiki's Research/PURe web
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe
The Research/PURe web of TWiki. TWiki is a Web-Based Collaboration Platform for the Corporate World.en-usCopyright 2020 by contributing authorsTWiki Administrator [webmaster@di.uminho.pt]The contributing authors of TWikiTWikiDIUM.Research/PURe
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe
/twiki/pub/Main/LocalLogos/um_eengP.jpgProjectSummary
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/ProjectSummary
Project Summary In a situation in which the only quality certificate of the running software artifact still is life cycle endurance, customers and software producers ... (last changed by LuisSoaresBarbosa)2009-03-02T19:23:42ZLuisSoaresBarbosaWebHome
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebHome
Program Understanding and Re engineering: Calculi and Applications The aim of the PURe research project is to develop calculi for program understanding and re engineering ... (last changed by LuisSoaresBarbosa)2009-03-02T19:18:53ZLuisSoaresBarbosa2LT
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/2LT
Two Level Transformation (2LT) NOTE: the 2LT project is moving to: at Google Code. A two level data transformation consists of a type level transformation of a data ... (last changed by TiagoAlves)2007-12-05T23:40:49ZTiagoAlvesWebSideBar
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebSideBar
Navigation Home PURe Café Publications Software Related Group Conferences IKF Project News (last changed by JoseBacelarAlmeida)2007-11-04T19:25:44ZJoseBacelarAlmeidaFlexibleSkinLeftBar
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/FlexibleSkinLeftBar
Project Home PURe Café Publications Software Related Group Conferences Books IKF Project Navigation Users Changes Index Statistics Webs Search (last changed by JoseBacelarAlmeida)2007-11-04T19:21:09ZJoseBacelarAlmeidaSdfMetz
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/SdfMetz
!SdfMetz: metrication of SDF grammars !SdfMetz computes metrics for SDF grammars. Among the supported metrics are counters of terminals, non terminals, productions ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaPURePublications
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PURePublications
Project Publications and Reports Publications (Conference Papers) On the Specification of a Component Repository , Rodrigues, N. and Barbosa, L., FACS'03 (Int ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaPUReNewsArchive
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReNewsArchive
See also recent PURe news. News archive 2006 (until March) March, 25 The lambda coinduction by calculation stuff was presented today in Wien by AlexandraSilva ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaHaGLR
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/HaGLR
What is HaGLR? HaGLR provides support for Generalized LR parsing in Haskell. Documentation João Saraiva, João Fernandes, and Joost Visser. Generalized LR Parsing ... (last changed by JoseBacelarAlmeida)2007-11-04T19:18:26ZJoseBacelarAlmeidaCamila
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/Camila
CAMILA: VDM meets Haskell The Camila project explores how concepts from the VDM specification language and the functional programming language Haskell can be combined ... (last changed by JoseBacelarAlmeida)2007-11-04T18:58:50ZJoseBacelarAlmeidaCoddFish
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/CoddFish
!CoddFish !CoddFish is a Haskell library that offers strongly typed support for database programming. Documentation !CoddFish makes extensive use of heterogenous ... (last changed by JoostVisser)2007-07-11T21:47:50ZJoostVisserXsdMetz
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/XsdMetz
!XsdMetz The !XsdMetz tool computes metrics for XML schemas. Documentation !XsdMetz was developed to support the structure metrics defined in the following publication ... (last changed by JoostVisser)2007-07-11T21:47:15ZJoostVisserPUReCafe
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReCafe
As of September 2006, PUReCafe has been continued with a wider scope as the Theory and Formal Methods Seminar. PUReCafe was a weekly scientific colloquium organized ... (last changed by JoseBacelarAlmeida)2007-06-28T11:45:16ZJoseBacelarAlmeidaPUReCafeTalk1
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/PUReCafeTalk1
Invitation to Wiki Basic Principles WikiName TextFormattingRules Edit via browser Distributed ownership Successful Wikis ... (last changed by JoseBacelarAlmeida)2007-06-28T11:42:14ZJoseBacelarAlmeidaWebTopicActions
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebTopicActions
(last changed by JoseBacelarAlmeida)2007-05-29T16:23:54ZJoseBacelarAlmeidaWebSearchAdvanced
http://wiki.di.uminho.pt/twiki/bin/view/Research/PURe/WebSearchAdvanced
(last changed by TWikiGuest)2007-05-17T14:51:23Zguest
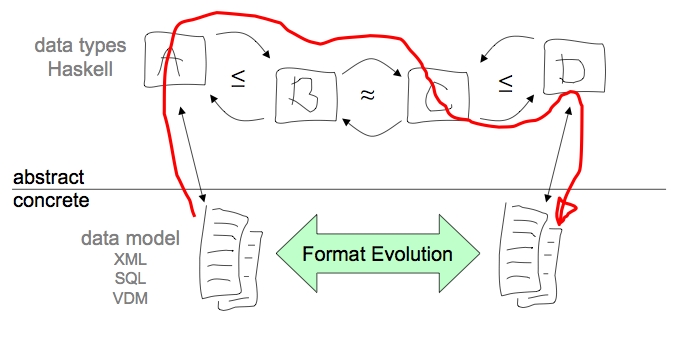
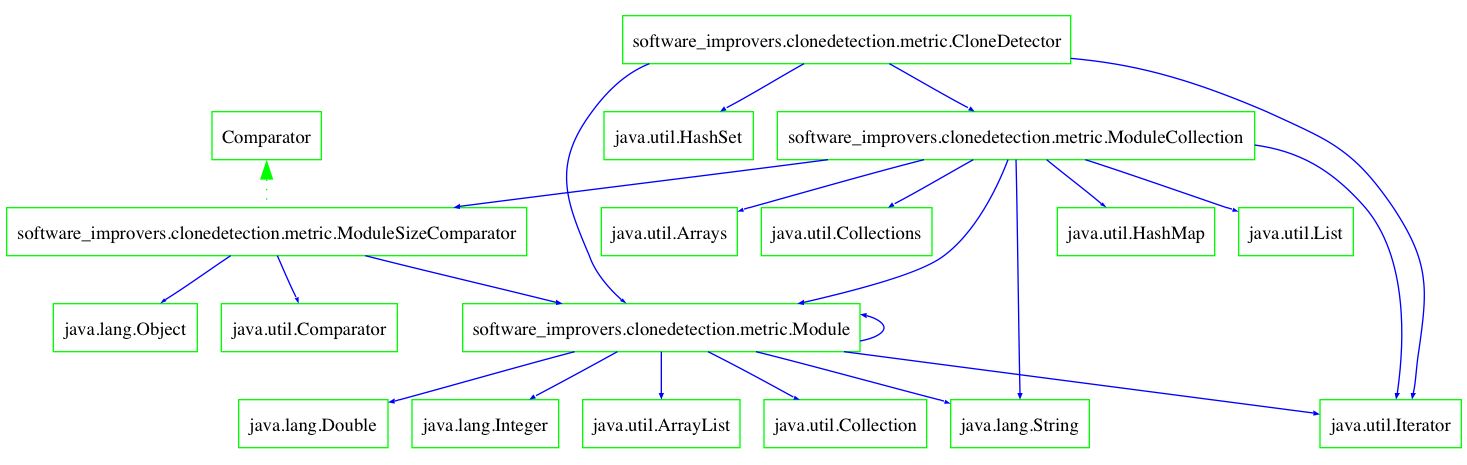
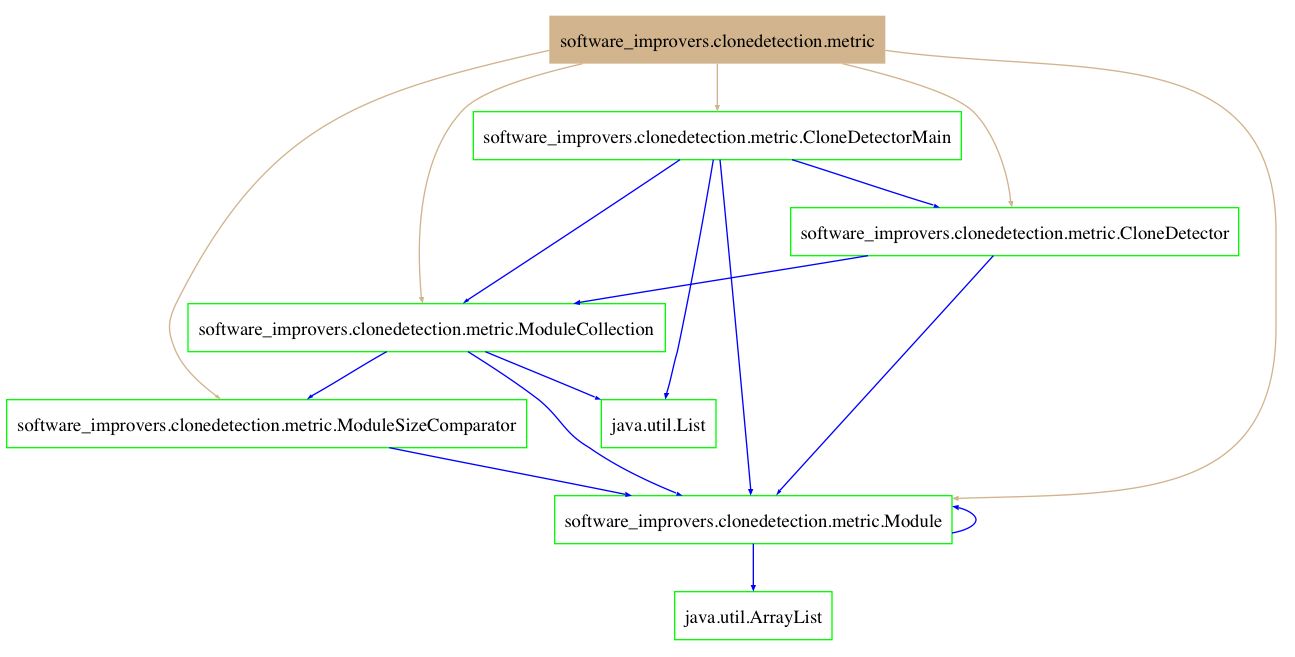
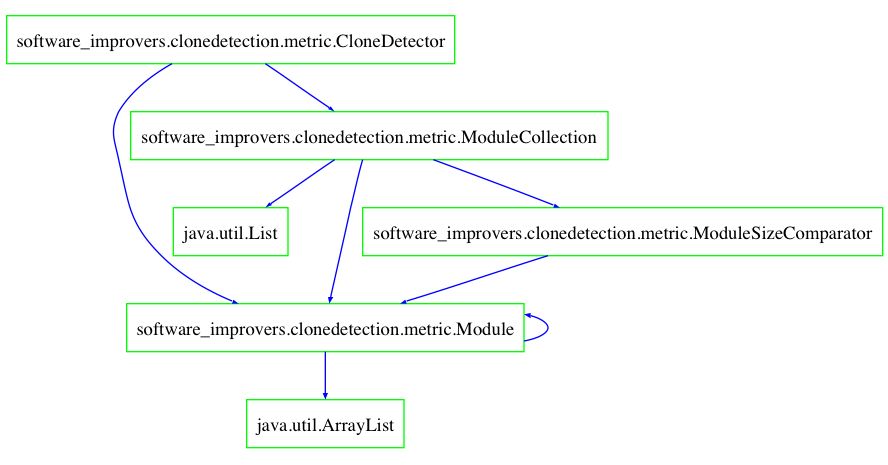

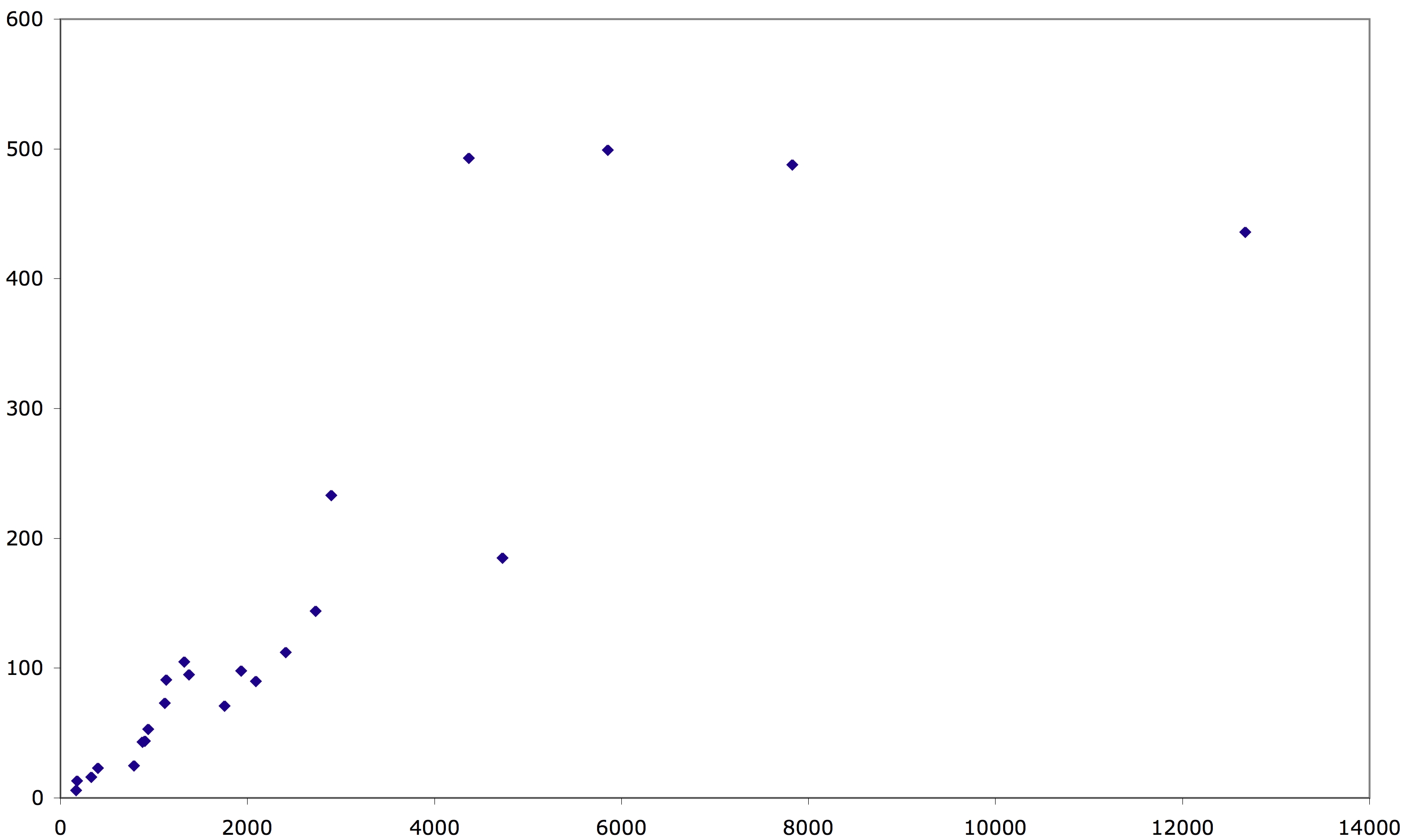
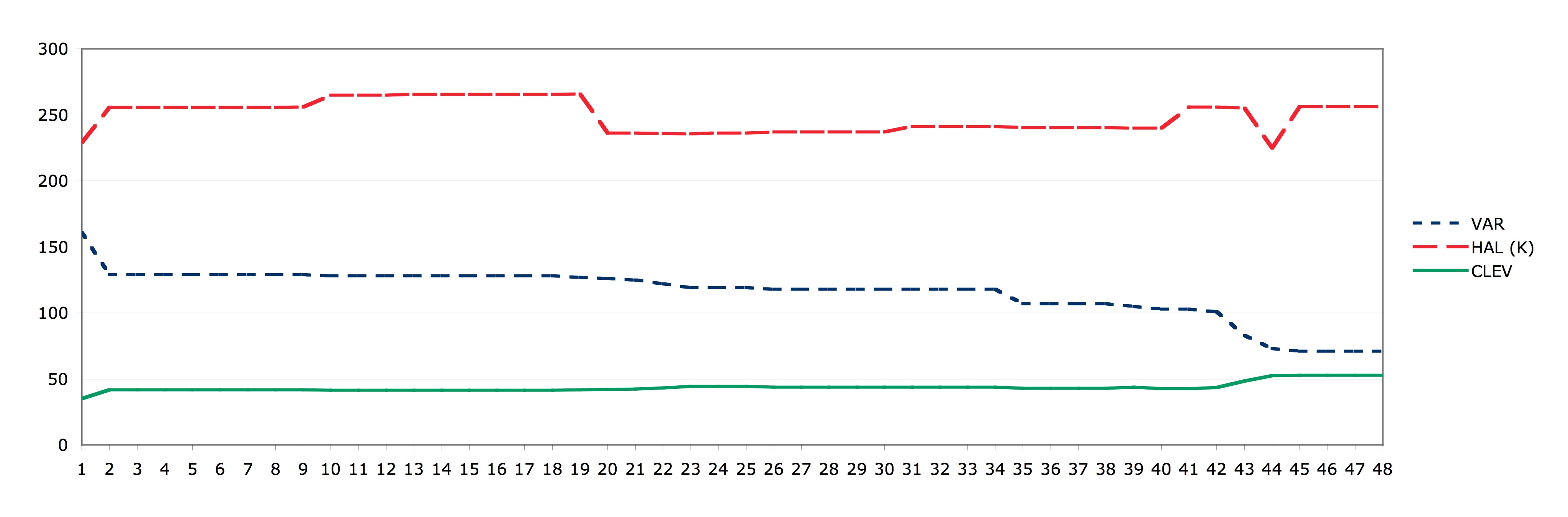

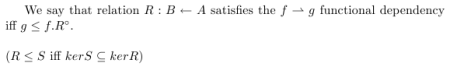 Selected Publications
Selected Publications